.avif)


Ask any security practitioner what keeps them up at night, and it rarely comes down to a specific tool. It's usually the data itself – is it complete, trustworthy, and reaching the right place at the right time?
Pipelines are the arteries of modern security operations. They carry logs, metrics, traces, and events from every layer of the enterprise. Yet in too many organizations, those arteries are clogged, fragmented, or worse, controlled by someone else.
That was the central theme of our webinar, From Chaos to Clarity, where Allie Mellen, Principal Analyst at Forrester, and Mark Ruiz, Sr. Director of Cyber Risk and Defense at BD, joined our CPO Aditya Sundararam and our CISO Preston Wood.
Together, their perspectives cut through the noise: analysts see a market increasingly pulling practitioners into vendor-controlled ecosystems, while practitioners on the ground are fighting to regain independence and resilience.
The Analyst's Lens: Why Neutral, Open Pipelines Matter
Allie Mellen spends her days tracking how enterprises buy, deploy, and run security technologies. Her warning to practitioners is direct: control of the pipeline is slipping away.
The last five years have seen unprecedented consolidation of security tooling. SIEM vendors offer their own ingestion pipelines. Cloud hyperscalers push their monitoring and telemetry services as defaults. Endpoint and network vendors bolt on log shippers designed to funnel telemetry back into their ecosystems.
It all looks convenient at first. Why not let your SIEM vendor handle ingestion, parsing, and routing? Why not let your EDR vendor auto-forward logs into its own analytics console?
Allie's answer: because convenience is control and you're not the one holding it.
" Practitioners are looking for a tool much like with their SIEM tool where they want something that is independent or that’s kind of how they prioritize this "
— Allie Mellen, Principal Analyst, Forrester
This erosion of control has real consequences:
- Vendor lock-in: Once you're locked into a vendor's pipeline, swapping tools downstream becomes nearly impossible. Want to try a new analytics platform? Your data is tied up in proprietary formats and routing rules.
- Blind spots: Vendor-native pipelines often favor data that benefits the vendor's use cases, not the practitioners’. This creates gaps that adversaries can exploit.
- AI limitations: Every vendor now advertises "AI-driven security." But as Allie points out, AI is only as good as the data it ingests. If your pipeline is biased toward one vendor's ecosystem, you'll get AI outcomes that reflect their blind spots, not your real risk.
For Allie, the lesson is simple: net-neutral pipelines are the only way forward. Practitioners must own routing, filtering, enrichment, and forwarding decisions. They must have the ability to send data anywhere, not just where one vendor prefers.
That independence is what preserves agility, the ability to test new tools, feed new AI models, and respond to business shifts without ripping out infrastructure.
The Practitioner's Challenge: BD's Story of Data Chaos
Theory is one thing, but what happens when practitioners actually lose control of their pipelines? For Becton Dickinson (BD), a global leader in medical technology, the consequences were very real.
BD's environment spanned hospitals, labs, cloud workloads, and thousands of endpoints. Each vendor wanted to handle telemetry in its own way. SIEM agents captured one slice, endpoint tools shipped another, and cloud-native services collected the rest.
The result was unsustainable:
- Duplication: Multiple vendors forwarding the same data streams, inflating both storage and licensing costs.
- Blind spots: Medical device telemetry and custom application logs didn't fit neatly into vendor-native pipelines, leaving dangerous gaps.
- Operational friction: Pipeline management was spread across several vendor consoles, each with its own quirks and limitations.
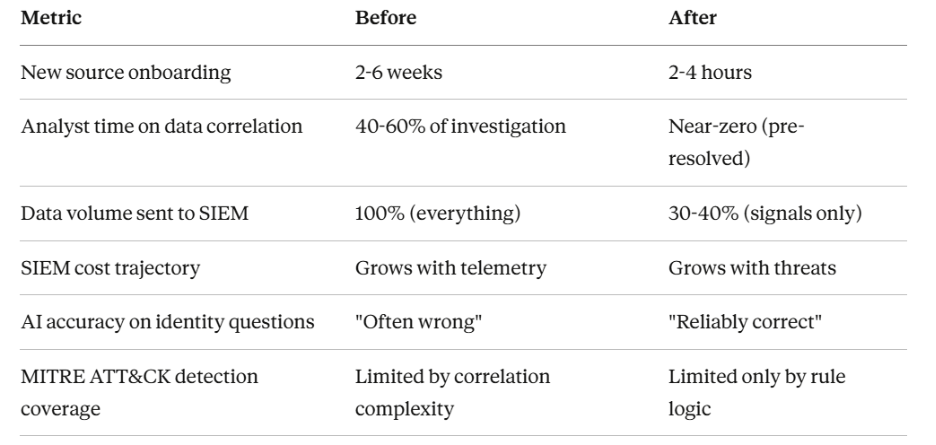
For BD's security team, this wasn't just frustrating, it was a barrier to resilience. Analysts wasted hours chasing duplicates while important alerts slipped through unseen. Costs skyrocketed, and experimentation with new analytics tools or AI models became impossible.
Mark Ruiz, Sr. Director of Cyber Risk and Defense at BD, knew something had to change.
With Databahn, BD rebuilt its pipeline on neutral ground:
- Universal ingestion: Any source from medical device logs to SaaS APIs could be onboarded.
- Scalable filtering and enrichment: Data was cleaned and streamlined before hitting downstream systems, reducing noise and cost.
- Flexible routing: The same telemetry could be sent simultaneously to Splunk, a data lake, and an AI model without duplication.
- Practitioner ownership: BD controlled the pipeline itself, free from vendor-imposed limits.
The benefits were immediate. SIEM ingestion costs dropped sharply, blind spots were closed, and the team finally had room to innovate without re-architecting infrastructure every time.
" We were able within about eight, maybe ten weeks consolidate all of those instances into one Sentinel instance in this case, and it allowed us to just unify kind of our visibility across our organization."
— Mark Ruiz, Sr. Director, Cyber Risk and Defense, BD
Where Analysts and Practitioners Agree
What's striking about Allie's analyst perspective and Mark's practitioner experience is how closely they align.
Both argue that convenience isn't resilience. Vendor-native pipelines may be easy up front, but they lock teams into rigid, high-cost, and blind-spot-heavy futures.
Both stress that pipeline independence is fundamental. Whether you're defending against advanced threats, piloting AI-driven detection, or consolidating tools, success depends on owning your telemetry flow.
And both highlight that resilience doesn't live in downstream tools. A world-class SIEM or an advanced AI model can only be as good as the data pipeline feeding it.
This alignment between market analysis and hands-on reality underscores a critical shift: pipelines aren't plumbing anymore. They're infrastructure.
The Databahn Perspective
For Databahn, this principle of independence isn't an afterthought—it's the foundation of the approach.
Preston Wood, CSO at Databahn, frames it this way:
"We don't see pipelines as just tools. We see them as infrastructure. The same way your network fabric is neutral, your data pipeline should be neutral. That's what gives practitioners control of their narrative."
— Preston Wood, CSO, Databahn
This neutrality is what allows pipelines to stay future-proof. As AI becomes embedded in security operations, pipelines must be capable of enriching, labeling, and distributing telemetry in ways that maximize model performance. That means staying independent of vendor constraints.
Aditya Sundararam, CPO at Databahn, emphasizes this future orientation: building pipelines today that are AI-ready by design, so practitioners can plug in new models, test new approaches, and adapt without disruption.
Own the Pipeline, Own the Outcome
For security practitioners, the lesson couldn't be clearer: the pipeline is no longer just background infrastructure. It's the control point for your entire security program.
Analysts like Allie warn that vendor lock-in erodes practitioner control. Practitioners like Mark show how independence restores visibility, reduces costs, and builds resilience. And Databahn's vision underscores that independence isn't just tactical, it's strategic.
So the question for every practitioner is this: who controls your pipeline today?
If the answer is your vendor, you've already lost ground. If the answer is you, then you have the agility to adapt, the visibility to defend, and the resilience to thrive.
In security, tools will come and go. But the pipeline is forever. Own it, or be owned by it.

.png)











.avif)

.avif)







