Network flow data is one of the most underutilized sources of telemetry in enterprise security.
Not because it lacks value. NetFlow, sFlow, and IPFix reveal traffic patterns, lateral movement, and network behavior that firewalls, EDR, and cloud security tools simply cannot see. Flow data fills visibility gaps across hybrid networks, especially in regions where deploying traditional security tooling is impractical or impossible.
Teams know this. They understand flow data matters.
The problem is that getting flow data into a SIEM is unnecessarily complex. SIEM vendors don't support flow protocols natively. Teams are left building conversion pipelines, deploying NetFlow collectors, configuring stream forwarders, and wrestling with high-volume ingestion costs. The infrastructure required to make flow data useful often makes it not worth the effort.
So flow data gets deprioritized. The visibility gaps remain.
The Current Reality: Three Bad Options
When it comes to flow data ingestion, most security teams end up choosing between approaches that all have significant downsides:
Option 1: Build conversion layers: Deploy NetFlow collectors, configure forwarders, convert flow records to syslog or HTTP formats that SIEMs can ingest. This approach works, but it's brittle. Conversion pipelines break when devices get upgraded, when flow templates change, when new versions of NetFlow or IPFix are introduced. Each failure creates a blind spot until someone notices and fixes it.
Option 2: Send raw flow data directly to the SIEM: Skip the intermediary layers and point flow exporters straight at the SIEM. The problem? Flow data is high-volume and noisy. Without intelligent filtering and aggregation, raw flow records flood SIEMs with redundant, low-value events. Ingestion costs explode. SIEM performance degrades. Teams end up paying for noise.
Option 3: Skip flow data entirely: Accept the visibility gaps. Rely on what firewalls, endpoints, and cloud logs can show. Hope that lateral movement, data exfiltration, and shadow IT don't happen in the parts of the network you can't see.
None of these options are good. But for most teams, one of these three is reality. The root cause? SIEM vendors have historically treated flow data as an edge case. Most platforms don't support flow protocols natively.
This is where Databahn comes in.
Databahn's Flow Collector: Direct Ingestion, Zero Middleware
Databahn's Flow Collector was built to eliminate the unnecessary complexity of flow data ingestion. Instead of forcing flow records through conversion pipelines or accepting the cost explosion of raw SIEM ingestion, the Flow Collector receives NetFlow, sFlow, and IPFix directly via UDP, normalizes the data to JSON, and applies intelligent filtering before it ever reaches the SIEM.
How It Works
The Flow Collector listens directly on the network for flow records sent over UDP. Point your flow exporters—routers, switches, firewalls—at Databahn's Smart Edge Collector. Configure the source using pre-defined templates for collection, normalization, filtering, and transformation. That's it.
Behind the scenes, the platform handles the complexity:
Protocol support across versions: NetFlow (v5, v7, v9), sFlow, IPFix — every major flow protocol and version are supported natively. No custom parsers. No version-specific workarounds.
Automatic normalization: Flow records arrive in different formats with varying field structures. The Flow Collector converts them to a consistent JSON format, making downstream processing straightforward.
Intelligent volume control: Flow data is noisy. Duplicate records, low-priority flows, redundant session updates, all of this inflates ingestion cost without delivering insight. Databahn filters, aggregates, and deduplicates flow data before it reaches the SIEM, ensuring only relevant, curated events are ingested.
After: Direct ingestion. Automatic normalization. Intelligent filtering at the edge. Complete network visibility without operational complexity or runaway costs.
Flow data becomes what it should have been from the start: straightforward, cost-controlled, and foundational to how you see your network.
No More Trade-Offs
Flow data has always been valuable. What’s changed is that collecting it no longer requires accepting operational complexity or budget explosions.
Databahn’s Flow Collector removes those trade-offs. Flow data stops being the thing security teams know they should collect but can’t justify the effort. It becomes what it should have been from the start: straightforward, cost-controlled, and foundational to how you see your network.
The visibility gaps in your network aren’t inevitable. The infrastructure just needed to catch up.
Databahn’s Flow Collector is available as part of the Databahn platform. Want to see how it handles your network architecture? Request a demo or talk to our team about your flow data challenges.
For years, enterprises have been told a comforting story: telemetry is telemetry. Logs are logs. If you can collect, normalize, and route data efficiently, you can support both observability and security from the same pipeline.
At first glance, this sounds efficient. One ingestion layer. One set of collectors. One routing engine. Lower cost. Cleaner architecture. But this story hides a fundamental mistake.
Observability, telemetry, and security telemetry are not simply two consumers of the same data stream. They are different classes of data with distinctintents, time horizons, economic models, and failure consequences.
The issue is intent. This is what we at Databahn call the Telemetry Intent Gap: the structural difference between operational telemetry and adversarial telemetry. Ignoring this gap is quietly eroding security outcomes across modern enterprises.
The Convenient Comfort of ‘One Pipeline’
The push to unify observability and security pipelines didn’t stem from ignorance. It stemmed from pressure. Exploding data volumes and rising SIEM costs which outstrip CISO budgets and their data volumes are exploding. Costs are rising. Security teams are overwhelmed. Platform teams are tired of maintaining duplicate ingestion layers. Enterprises want simplification.
At the same time, a new class of vendors has emerged,positioning themselves between observability and security. They promise a shared telemetry plane, reduced ingestion costs, and AI-powered relevance scoring to “eliminate noise.” They suggest that intelligent pattern detection can determine which data matters for security and keep the rest out ofSIEM/SOAR threat detection and security analytics flows.
On paper, this sounds like progress. In practice, it risks distorting security telemetry into something it was never meant to be.
Observability reflects operational truths, not security relevance
From an observability perspective, telemetry exists to answer a narrow but critical question: Is the system healthy right now? Metrics, traces, and debug logs are designed to detect trends, analyze latency, measure error rates, and identify performance degradation. Their value is statistical. They are optimized for aggregation, sampling, and compression. If a metric spike is investigated and resolved, the granular trace data may never be needed again. If a debug logline is redundant, suppressing it tomorrow rarely creates risk. Observability data is meant to be ephemeral by design: its utility decays quickly, and its value lies in comparing the ‘right now’ status to baselines or aggregations to evaluate current operational efficiency.
This makes it perfectly rational to optimize observability pipelines for:
· Volume reduction
· Sampling
· Pattern compression
· Short- to medium-term retention
The economic goal is efficiency. The architectural goal isspeed. The operational goal is performance stability. Now contrast that with security telemetry.
Security telemetry is meant for adversarial truth
Security telemetry exists to answer a very different question: Did something malicious happen – even if we don't yet know what or who it is?
Security telemetry is essential. Its value is not statistical but contextual. An authentication event that appears benign today may become critical evidence two years later during an insider threat investigation. A low-frequency privilege escalation may seem irrelevant until it becomes part of a multi-stage attack chain. A lateral movement sequence may span weeks across multiple systems before becoming visible. Unlike observability telemetry, security telemetry is often valuable precisely because it resists pattern compression.
Attack behavior does not always conform to short-term statistical anomalies. Adversaries deliberately operate below detection thresholds. They mimic normal behavior. They stretch activity over long time horizons. They exploit the fact that most systems optimize for recent relevance. Security relevance is frequently retrospective, and this is where the telemetry intent gap becomes dangerous.
The Telemetry Intent Gap
This gap is not about format or data movement. It is about the underlying purpose of two different types of data. Observability pipelines are meant to uncover and track performance truth, while security pipelines are meant to uncover adversarial truth.
Observability asks: Is this behavior normal? Is the data statistically consistent? Security asks: Does the data indicate malicious intent? In observability, techniques such as sampling and compression to aggregate and govern data make sense. In security, all potential evidence and information should be maintained and accessible, and kept in a structured, verifiable manner. Essentially, how you treat – and, at a design level, what you optimize for – in your pipeline strongly impacts outcomes. When telemetry types are processed through the same optimization strategy, one of them loses. And in most enterprises, the cost of retaining and managing all data puts the organization's security posture at risk.
The Rise of AI-powered ‘relevance’
In response to cost pressure, a growing number of vendors catering to observability and security telemetry use cases claim to solve this problem with AI-driven relevance scoring. Their premise is simple: use pattern detection to determine which logs matter, and drop/reroute the rest. If certain events have not historically triggered investigations or alerts, they are deemed low-value and suppressed upstream.
This approach mirrors observability logic. It assumes that medium-term patterns define value. It assumes that the absence of recent investigations or alerts implies no or low risk. For observability telemetry, this may be acceptable.
For security telemetry, this is structurally flawed. Security detection itself is pattern recognition – but of a much deeper kind. It involves understanding adversarial tradecraft, long-term behavioral baselines and rare signal combination that may never have appeared before. Many sophisticated attacks accrue slowly, and involve malicious action with low-and-slow privilege escalation, compromised dormant credentials, supply chain manipulation, and cloud misconfiguration abuse. These behaviors do not always trigger immediate alerts. They often remain dormant until correlated with events months or years later.
An observability-first AI model trained on short-term usage patterns may conclude that such telemetry is "noise". It may reduce ingestion based on absence of recent alerts. It may compress away low-frequency signals. But absence of investigations is not the absence of threats. Security relevance is often invisible until context accumulates. The timeline over which security data would find relevance is not predictable, and making short and medium-term judgements on the relevance of security data is a detriment to long-horizon detection and forensic reconstruction.
When Unified Pipelines Quietly Break Security
The damage does not announce itself loudly. It appears as:
· Missing context during investigations
· Incomplete event chains
· Reduced ability to reconstruct attacker movement
· Inconsistent enrichment across domains
· Silent blind spots
Detection engineers often experience this in terms of fragility: rules are breaking, investigations are stalling, and data must be replayed from cold storage – if it exists. SOC teams lose confidence in their telemetry, and the effort to ensure telemetry 'completeness' or relevance becomes a balancing act between budget and security posture.
Meanwhile, platform teams believe the pipeline is functioning perfectly – it is running smoothly, operating efficiently, and cost-optimized. Both teams are correct, but they are optimizing for different outcomes. This is the Telemetry Intent Gap in action.
This is not a Data Collection issue
It is tempting to frame this as a tooling or ingestion issue. But this isn't about that. There is no inherent challenge in using the same collectors, transport protocols, or infrastructure backbone. What must differ is the pipeline strategy. Security telemetry requires:
· Early context preservation
· Relevance decisions informed by adversarial models, not usage frequency
· Asymmetric retention policies
· Separation of security-relevant signals from operational exhaust
· Long-term evidentiary assumptions
Observability pipelines are not wrong. They are simply optimized for a different purpose. The mistake is in believing that the optimization logic is interchangeable.
The Business Consequence
When enterprises blur the line between observability and security telemetry, they are not just risking noisy dashboards. They are risking investigative integrity. Security telemetry underpins compliance reporting, breach investigations, regulatory audits, and incident reconstruction. It determines whether an enterprise can prove what happened – and when.
Treating it as compressible exhaust because it did not trigger recent alerts is a dangerous and risky decision. AI-powered insights without security context will often over index on short and medium term usage patterns, leading to a situation where the mechanics and costs of data collection obfuscate a fundamental difference in business value.
Operational telemetry supports system reliability. Security telemetry supports enterprise resilience. These are not equivalent mandates, and treating them similarly leads to compromises on security posture that are not tenable for enterprise stacks.
Towards intent-aware pipelines
The answer is not duplicating infrastructure. It is designing pipelines that understand intent. An intent-aware strategy acknowledges:
· Some data is optimized for performance efficiency
· Some data is optimized for adversarial accountability
· The same transport can support both, but the optimization logic – and the ability to segment and contextually treat and distinguish this data – is critical
This is where purpose-built security data platforms are emerging – not as generic routers, and not as observability engines extended into security, but as infrastructure optimized for adversarial telemetry from the start.
Platforms designed with security intent as their core – and not observability platforms extending into the security 'use case – do not define the value of data by their recent pattern frequency alone. They are opinionated, have a contextual understanding of security relevance, and are able to preserve and even enrich and connect data to enable long-term reconstruction. They treat telemetry as evidence, not exhaust.
That architectural stance is not a feature. It is a philosophy. And it is increasingly necessary.
Observability and Security can share pipes – not strategy
The enterprise temptation to unify telemetry is understandable. The cost pressures are real. The operational fatigue is real. But conflating optimization logic across observability and security is not simplification. It is misalignment. The future of enterprise telemetry is not a single, flattened data stream scored by generic AI relevance. It is a layered architecture that respects the Telemetry Intent Gap.
The difference between operational optimization and adversarial investigation can coexist and share infrastructure, but they cannot share strategy. Recognizing this difference may be one of the most important architectural decisions security and platform leaders make in the coming decade.
Before starting Databahn, we spent years working alongside large enterprise security teams. Across industries and environments, we kept encountering the same pattern: the increased sophistication of platform and analytics in modernized stacks, matched by the fragility of the security data layer.
Data is siloed across tools, movement is inefficient, lineage is a mystery that requires investigation. Governance is inconsistent, and management is a manual exercise leaning heavily on engineering bandwidth not being spent on delivering clarity, but in keeping systems going despite obvious gaps. Every new initiative depended on data that was harder to manage than it should have been. It became clear to us that this was not an operational inconvenience but a structural problem.
We started Databahn with a simple conviction: that to improve detection logic, ensure scalable AI implementation, and accelerate and optimize security operations, security data itself has to be made to work. That conviction has driven every decision we have made.
This week, we shared that Databahn has grown by more than 400% year-on-year, with more than half of our customers from the Fortune 500. We are deeply grateful to the enterprises, partners, and team members who have trusted us to solve this challenge alongside them. But the growth and traction are not the headline. It is that the security ecosystem is recognizing what we saw years ago – security data is the foundation of modern security operations.
Our strategy – staying focused
As the market evolves, companies face choices about where to direct their energy. There is always pressure to broaden and extend into adjacencies, or to join up and be absorbed by larger players in the security ecosystem.
At Databahn, we remain singularly focused on solving the enterprise security data problem. Our customers and partners rely on us to be a best-of-breed solution for security data management, not a competitor attempting to replace parts of their ecosystem with new capabilities that dilute our mission.
It needs to move cleanly across environments to different tools. It needs to be governed and optimized. It should support existing systems without creating friction. Building the security data system that delivers the right security data to the right place at the right time with the right context is the problem we are choosing to solve for our customers.
Enterprise adoption reflects a larger shift
The enterprises choosing Databahn are not experimenting; they are standardizing.
A Fortune 100 global airline managed a complex SIEM migration in just 6 weeks, while ensuring that complex data types – flight logs, sensors, etc. were seamlessly ingested and managed across the organization. The result was a more resilient and controlled data foundation, ready for AI deployment and optimized for scale and efficiency.
Sunrun reduced log volume by 70% while improving visibility across its complex and geographically distributed environment. That shift translated into meaningful cost efficiency and stronger signal clarity.
Working with these exceptional global teams to turn security data noise into manageable and optimized signal validates our conviction. Our growth is a reflection of this realization taking hold inside the enterprise – security data isn’t working right now, but it can be made to work.
Security Data is now strategic architecture
As enterprises accelerate modernization and AI-driven initiatives, expectations placed on data have fundamentally changed. Security data is no longer exhaust, but it is infrastructure. It is the platform on which the future AI-powered SOC must operate. It must be portable, governed, observable, and adaptable to new systems without forcing architectural trade-offs.
Enterprises cannot build intelligent workflows on unstable data foundations, where teams can’t trust their telemetry, and so must trust their AI output based on that telemetry even less. Before you layer more intelligence on top of your security stack, you have to fix the data foundation. That’s why AI transformation is being led by Forward Deployment Engineers who are structuring and cleansing data before adding AI solutions on top. Databahn provides that foundation as a platform, delivering flexible resiliency and governance without the manual effort and tech debt.
What comes next
We believe the next chapter of enterprise security will be defined by organizations that treat security data as a strategic asset rather than an operational byproduct. Our commitment is to continue going deeper into solving that core problem. To strengthen partnerships across the ecosystem and help enterprises modernize their security architecture without being forced into unnecessary complexity or locked into a platform that prevents ownership of their data.
The momentum we announced this week is meaningful, but it is just the beginning of a movement. What matters more is what it represents. That enterprises need to make their security data actually work.
We are excited to continue solving that challenge alongside the leaders driving this shift. The future holds many exciting new partnerships, product development, and other ways we can reduce complexity and increase ownership and value of security data. If any of these challenges seem relatable, we would invite you to get in touch with us to see if we can help.
The Open Cybersecurity Schema Framework (OCSF) was designed to solve a fundamental problem: security data fragmentation. By offering an open and shared format, OCSF brought a shared foundational understanding of what security data should be understood, driving consistency. But every security engineer who has implemented OCSF mappings encounters the same structural challenge within weeks: the unmapped object.
This is where normalization efforts stall.
The Unmapped Object, Defined
OCSF aims to resolve fragmentation in security data by providing a shared taxonomy, including categories, event classes, and a standardized attribute dictionary, so that telemetry from disparate sources can be queried, correlated, and analyzed consistently. But this structure runs into challenges for complex and unexpected security data which does not fall neatly into the framework.
OCSF defines the unmapped object as a catch-all container for source data that doesn't map cleanly to standardized attributes. When an engineer translates a firewall log into OCSF format, fields like source IP become src_endpoint.ip, usernames normalize to actor.user.name, and timestamps align to time. These are the wins.
But source telemetry routinely contains fields that have no standard home in the schema. An MFA status indicator from an identity provider. A proprietary risk score from an EDR vendor. A vendor-specific context field that detection logic depends on. These fields don't disappear, they land in unmapped.
The unmapped object preserves data. Technically, nothing is lost. But it creates a different kind of fragmentation: structured, queryable fields alongside unstructured data that requires custom parsing for every downstream consumer. Detection engineers writing correlation rules cannot rely on unmapped content without building source-specific logic. Analysts hunting for threats must know which unmapped fields exist and how to extract them. AI systems attempting to reason across security data cannot process unmapped content without additional transformation.
The richer the source telemetry, the more content ends up unmapped. As one industry analysis observed: "Data is custom, the richer the data the more unmappable it gets. Don't be surprised if the analyst goes digging into un-normalized fields rather than common normalized fields, because that's where the piece of information they needed was buried."
This is the structural tension at the heart of OCSF adoption.
Three Causes of Mapping Gaps
Three factors drive the unmapped problem.
Schema variability at the source. Security tools emit logs in formats designed for their own ecosystems, not for interoperability. Proprietary field names, nested structures, and vendor-specific semantics mean that mapping requires deep understanding of both source format and target schema. When a vendor changes their log format, adding fields or restructuring existing ones, transformation rules break. Fields that were previously mapped may suddenly require rework. The maintenance burden compounds across hundreds of data sources.
Partial schema coverage. Some security tools don't provide enough data or context to fully populate OCSF's structured fields. Missing event class identifiers, absent process metadata, incomplete user objects, these gaps force engineers to choose between extending the schema, dropping fields, or accepting degraded normalization fidelity. None of these options are cost-free.
Field conflicts and ambiguities. Different tools use the same field name for different purposes, or represent the same concept with incompatible structures. A "status" field in one product might indicate connection state; in another, it represents authentication outcome. Resolving these conflicts requires judgment calls that must be documented, maintained, and applied consistently across all pipelines handling that source.
Organizations adopt OCSF expecting unified telemetry. What they often get is a mix of cleanly mapped fields and growing unmapped buckets that require custom handling for every query, detection rule, and investigation workflow. Organizations report spending two to four months on comprehensive OCSF implementations, and that timeline assumes stable source schemas, which rarely hold.
Three Governance Approaches
Security teams handle unmapped content in three primary ways, each with distinct trade-offs.
Strict minimum mapping. Map only the fields explicitly required by OCSF for the chosen event class. Everything else goes to unmapped. This approach preserves data completeness and avoids over-engineering the mapping layer, but it pushes complexity downstream. Detection engineers must write custom parsers for unmapped content. Analysts lose the ability to correlate on fields that could have been standardized. This approach works for organizations with simple detection requirements or limited cross-source correlation needs. It fails when unmapped fields contain the precise context needed for threat hunting or incident response.
Schema extension. OCSF supports extensions, formal mechanisms to add custom attributes to existing event classes without breaking compatibility. For fields that are critical and represent long-term requirements, creating an organization-specific extension with dedicated attributes is the most robust solution. Extension requires registration to receive a unique identifier range, preventing conflicts with the core schema or other organizations' extensions. The process enforces governance but demands ongoing maintenance: schema registries to track which extensions exist, what they contain, and which pipeline versions support them. This approach fits organizations with mature data engineering capabilities and stable telemetry requirements. It struggles when sources change frequently or when teams lack resources for extension lifecycle management.
Dynamic classification. Rather than pre-defining every mapping or manually extending schemas, this approach uses intelligent systems to classify and route data in real time. The pipeline learns source schemas, identifies semantic equivalents, and maps fields dynamically, elevating what would be unmapped into structured, queryable attributes without manual rule creation.
This is where the architectural gap exists in most OCSF implementations. Static mapping rules cannot adapt to schema drift. Manual extension processes cannot scale to hundreds of sources. Unmapped buckets grow into ungovernable data graveyards.
Normalization as a Pipeline Problem
The unmapped field problem is fundamentally a pipeline architecture problem. Normalization happens in transit, not at rest. Decisions about what maps where, what extends the schema, and what falls into catch-all containers must be made in flight, at the speed of telemetry ingestion.
Traditional approaches treat parsing, normalization, and transformation as static configurations. Engineers write mapping rules, deploy them, and hope sources don't change. When they do, and sources always change, brittle pipelines break. Fields that should be normalized end up unmapped. Detection coverage degrades silently. No one notices until an investigation fails or a compliance audit surfaces gaps.
This is where Databahn comes in. The platform approaches OCSF normalization as a continuous, AI-assisted process rather than a one-time configuration exercise.
Cruz, Databahn's agentic AI, builds an understanding of source schemas as they evolve. It automatically detects schema drift and adapts transformations without manual intervention. When a vendor adds a new field or restructures an existing one, the pipeline doesn't break, it learns. Fields that would traditionally fall into unmapped buckets are intelligently classified and routed to appropriate schema locations, or flagged for extension when no suitable mapping exists.
The platform maintains schema consistency across heterogeneous data models in-line, rather than post-ingestion. This means SIEM correlation rules and detection logic operate on unified, structured data, not a mix of normalized fields and unmapped JSON blobs that require custom handling. Analysts spend time on investigations, not digging through catch-all containers for buried context.
For enterprises already navigating OCSF adoption with Amazon Security Lake, Microsoft Sentinel, or Splunk, Databahn provides the transformation layer that turns partial mappings into comprehensive normalization.
Governance Practices That Reduce Drift
Regardless of the approach chosen, governance practices reduce unmapped field accumulation over time.
Document every mapping decision. When a field goes to unmapped, record why. When an extension is created, define its scope and intended consumers. Detection engineers, data engineers, and analysts need to understand how data flows through the schema. Ambiguity compounds across teams and time.
Establish feedback loops with downstream consumers. The teams writing detection rules, hunting for threats, and investigating incidents are the first to know when unmapped fields contain critical context. Their pain points should drive mapping priorities and extension decisions.
Monitor unmapped field growth. If the unmapped object is expanding faster than structured fields, something is wrong architecturally. Either sources are changing faster than mappings can adapt, or the mapping strategy is too conservative for the organization's detection requirements.
Pin analytics and detection content to specific OCSF versions. Schema evolution is inevitable. Content repositories that reference explicit versions prevent breaking changes from silently degrading detection coverage when the schema updates.
The Architectural Choice
OCSF adoption is not a checkbox exercise. It is an architectural decision with downstream implications for every detection rule, investigation workflow, and AI application built on security data.
The unmapped field problem reveals a fundamental tension: static schemas cannot keep pace with dynamic telemetry. Organizations face a choice. Continue retrofitting manual mappings onto evolving sources, accepting growing unmapped buckets as inevitable. Or invest in infrastructure that treats normalization as a continuous, intelligent process, governance that happens in flight, not after storage.
The future of security data normalization is not more catch-all containers. It is pipelines that understand schemas, adapt to drift, and ensure that critical context reaches analysts and AI systems in structured, queryable form.
Attack Mechanism: After initial approval, malicious updates to approved MCP configs bypass review
Detection: Monitor approved MCP server config changes, diff analysis of mcp.json modifications
OpenClaw / Clawbot / Moltbot (2024-2026)
Category: Open-source personal AI assistant Impact: Subject of multiple CVEs including CVE-2025-53773 (CVSS 9.6) Installations: 100,000+ when major vulnerabilities disclosed
What is OpenClaw? OpenClaw (originally named Clawbot, later Moltbot before settling on OpenClaw) is an open-source, self-hosted personal AI assistant agent that runs locally on user machines. It can:
Execute tasks on user's behalf (book flights, make reservations)
Interface with popular messaging apps (WhatsApp, iMessage)
Store persistent memory across sessions
Run shell commands and scripts
Control browsers and manage calendars/email
Execute scheduled automations
Security Concerns:
Runs with high-level privileges on local machine
Can read/write files and execute arbitrary commands
Integrates with messaging apps (expanding attack surface)
Skills/plugins from untrusted sources
Leaked plaintext API keys and credentials in early versions
No built-in authentication (security "optional")
Cisco security research used OpenClaw as case study in poor AI agent security
Relation to Moltbook: Many Moltbook agents (the AI social network) used OpenClaw or similar frameworks to automate their posting, commenting, and interaction behaviors. The connection between the two highlighted how local AI assistants could be compromised and then used to propagate attacks through networked AI systems.
Key Lesson: OpenClaw demonstrated that powerful AI agents with system-level access require security-first design. The "move fast, security optional" approach led to numerous vulnerabilities that affected over 100,000 users.
Moltbook Database Exposure (February 2026)
Platform: Moltbook (AI agent social network - "Reddit for AI agents") Scale: 1.5 million autonomous AI agents, 17,000 human operators (88:1 ratio) Impact: Database misconfiguration exposed credentials, API keys, and agent data; 506 prompt injections identified spreading through agent network Attack Method: Database misconfiguration + prompt injection propagation through networked agents
What is Moltbook? Moltbook is a social networking platform where AI agents—not humans—create accounts, post content, comment on submissions, vote, and interact with each other autonomously. Think Reddit, but every user is an AI agent. Agents are organized into "submolts" (similar to subreddits) covering topics from technology to philosophy. The platform became an unintentional large-scale security experiment, revealing how AI agents behave, collaborate, and are compromised in networked environments.
Lessons: Natural experiment in AI agent security at scale
Key Findings:
Prompt injections spread rapidly through agent networks (heartbeat synchronization every 4 hours)
88:1 agent-to-human ratio achievable with proper structure
Memory poisoning creates persistent compromise
Traditional security missed database exposure despite cloud monitoring
Common Attack Patterns
Direct Prompt Injection: Ignore previous instructions <SYSTEM>New instructions:</SYSTEM> You are now in developer mode Disregard safety guidelines
Indirect Prompt Injection: Hidden in emails, documents, web pages White text on white background HTML comments, CSS display:none Base64 encoding, Unicode obfuscation
Data Exfiltration: Large API responses (>10MB) High-frequency tool calls Connections to attacker-controlled servers Environment variable leakage in HTTP headers
Today’s SOCs don’t have a detection or an AI readiness problem. They have a data architecture problem. Enterprise today are generating terabytes of security telemetry daily, but most of it never meaningfully contributes to detection, investigation, or response. It is ingested late and with gaps, parsed poorly, queried manually and infrequently, and forgotten quickly. Meanwhile, detection coverage remains stubbornly low and response times remain painfully long – leaving enterprises vulnerable.
This becomes more pressing when you account for attackers using AI to find and leverage vulnerabilities. 41% of incidents now involve stolen credentials(Sophos, 2025), and once access is obtained, lateral movement can begin in as little as two minutes. Today’s security teams are ill-equipped and ill-prepared to respond to this challenge.
The industry’s response? Add AI. But most AI SOC initiatives are cosmetic. A conversational layer over the same ingestion-heavy and unreliable pipeline. Data is not structured or optimized for AI deployments. What SOCs need today is an architectural shift that restructures telemetry, reasoning, and action around enabling security teams to treat AI as the operating system and ensure that their output is designed to enable the human SOC teams to improve their security posture.
The Myth Most Teams Are Buying
Most “AI SOC” initiatives follow a similar pattern. New intelligence is introduced at the surface of the system, while the underlying architecture remains intact. Sometimes this takes the form of conversational interfaces. Other times it shows up as automated triage, enrichment engines, or agent-based workflows layered onto existing SIEM infrastructure.
This ‘bolted-on’ AI interface only incrementally impacts the use, not the outcomes. What has not changed is the execution model. Detection is still constrained by the same indexes, the same static correlation logic, and the same alert-first workflows. Context is still assembled late, per incident, and largely by humans. Reasoning still begins after an alert has fired, not continuously as data flows through the environment.
This distinction matters because modern attacks do not unfold as isolated alerts. They span identity, cloud, SaaS, and endpoint domains, unfold over time, and exploit relationships that traditional SOC architectures do not model explicitly. When execution remains alert-driven and post-hoc, AI improvements only accelerate what happens after something is already detected.
In practice, this means the SOC gets better explanations of the same alerts, not better detection. Coverage gaps persist. Blind spots remain. The system is still optimized for investigation, not for identifying attack paths as they emerge.
That gap between perception and reality looks like this:
Each gap above traces back to the same root cause: intelligence added at the surface, while telemetry, correlation, and reasoning remain constrained by legacy SOC architecture.
Why Most AI SOC Initiatives Fail
Across environments, the same failure modes appear repeatedly.
1. Data chaos collapses detection before it starts Enterprises generate terabytes of telemetry daily, but cost and normalization complexity force selective ingestion. Cloud, SaaS, and identity logs are often sampled or excluded entirely. When attackers operate primarily in these planes, detection gaps are baked in by design. Downstream AI cannot recover coverage that was never ingested.
2. Single-mode retrieval cannot surface modern attack paths Traditional SIEMs rely on exact-match queries over indexed fields. This model cannot detect behavioral anomalies, privilege escalation chains, or multi-stage attacks spanning identity, cloud, and SaaS systems. Effective detection requires sparse search, semantic similarity, and relationship traversal. Most SOC architectures support only one.
3. Autonomous agents without governance introduce new risk Agents capable of querying systems and triggering actions will eventually make incorrect inferences. Without evidence grounding, confidence thresholds, scoped tool access, and auditability, autonomy becomes operational risk. Governance is not optional infrastructure; it is required for safe automation.
4. Identity remains a blind spot in cloud-first environments Despite being the primary attack surface, identity telemetry is often treated as enrichment rather than a first-class signal. OAuth abuse, service principals, MFA bypass, and cross-tenant privilege escalation rarely trigger traditional endpoint or network detections. Without identity-specific analysis, modern attacks blend in as legitimate access.
5. Detection engineering does not scale manually Most environments already process enough telemetry to support far higher ATT&CK coverage than they achieve today. The constraint is human effort. Writing, testing, and maintaining thousands of rules across hundreds of log types does not scale in dynamic cloud environments. Coverage gaps persist because the workload exceeds human capacity.
The Six Layers That Actually Work
A functional AI-native SOC is not assembled from features. It is built as an integrated system with clear dependency ordering.
Layer 1: Unified telemetry pipeline Telemetry from cloud, SaaS, identity, endpoint, and network sources is collected once, normalized using open schemas, enriched with context, and governed in flight. Volume reduction and entity resolution happen before storage or analysis. This layer determines what the SOC can ever see.
Layer 2: Hybrid retrieval architecture The system supports three retrieval modes simultaneously: sparse indexes for deterministic queries, vector search for behavioral similarity, and graph traversal for relationship analysis. This enables detection of patterns that exact-match search alone cannot surface.
Layer 3: AI reasoning fabric Reasoning applies temporal analysis, evidence grounding, and confidence scoring to retrieved data. Every conclusion is traceable to specific telemetry. This constrains hallucination and makes AI output operationally usable.
Layer 4: Multi-agent system Domain-specialized agents operate across identity, cloud, SaaS, endpoint, detection engineering, incident response, and threat intelligence. Each agent investigates within its domain while sharing context across the system. Analysis occurs in parallel rather than through sequential handoffs.
Layer 5: Unified case memory Context persists across investigations. Signals detected hours or days apart are automatically linked. Multi-stage attacks no longer rely on analysts remembering prior activity across tools and shifts.
Layer 6: Zero-trust governance Policies constrain data access, reasoning scope, and permitted actions. Autonomous decisions are logged, auditable, and subject to approval based on impact. Autonomy exists, but never without control.
Miss any layer, or implement them out of order, and the system degrades quickly.
Outcomes When the Architecture Is Correct
When the six layers operate together, the impact is structural rather than cosmetic:
Faster time to detection Detection shifts from alert-triggered investigation to continuous, machine-speed reasoning across telemetry streams. This is the only way to contend with adversaries operating on minute-level timelines.
Improved analyst automation L1 and L2 workflows can be substantially automated, as agents handle triage, enrichment, correlation, and evidence gathering. Analysts spend more time validating conclusions and shaping detection logic, less time stitching data together.
Broader and more consistent ATT&CK coverage Detection engineering moves from manual rule authoring to agent-assisted mapping of telemetry against ATT&CK techniques, highlighting gaps and proposing new detections as environments change.
Lower false-positive burden Evidence grounding, confidence scoring, and cross-domain correlation reduce alert volume without suppressing signal, improving analyst trust in what reaches them.
The shift from reactive triage to proactive threat discovery becomes possible only when architectural bottlenecks like fragmented data, late context, and human-paced correlation, are removed from the system.
Stop Retrofitting AI Onto Broken Architecture
Most teams approach AI SOC transformation backward. They layer new intelligence onto existing SIEM workflows and expect better outcomes, without changing the architecture that constrains how detection, correlation, and response actually function.
The dependency chain is unforgiving. Without unified telemetry, detection operates on partial visibility. Without cross-domain correlation, attack paths remain fragmented. Without continuous reasoning, analysis begins only after alerts fire. And without governance, autonomy introduces risk rather than reducing it.
Agentic SOC architectures are expected to standardize across enterprises within the next one to two years (Omdia, 2025). The question is not whether SOCs become AI-native, but whether teams build deliberately from the foundation up — or spend the next three years patching broken architecture while attackers continue to exploit the same coverage gaps and response delays.
When identity breaches cost an average of $4.8 million and 84% of organizations report direct business impact from credential attacks, you'd expect AI-powered security tools to be the answer.
Instead, security leaders are discovering that their shiny new AI copilots:
Miss obvious attack chains because user IDs don't match across systems
Generate confident-sounding analysis based on incomplete information
Can't answer simple questions like "show me everything this user touched in the last 24 hours"
The problem isn't artificial intelligence. It's artificial data quality.
Watch an Attack Disappear in Your Data
Here's a scenario that plays out daily in enterprise SOCs:
Attacker compromises credentials via phishing
Logs into cloud console → CloudTrail records arn:aws:iam::123456:user/jsmith
Exfiltrates via collaboration tool → Slack logs U04ABCD1234
Five steps. One attacker. One victim.
Your SIEM sees five unrelated events. Your AI sees five unrelated events. Your analysts see five separate tickets. The attacker sees one smooth path to your data.
This is the identity stitching problem—and it's why your AI can't trace attack paths that a human adversary navigates effortlessly.
Why Your Security Data Is Working Against You
Modern enterprises run on 30+ security tools. Here's the brutal math:
Enterprise SIEMs process an average of 24,000 unique log sources
Those same SIEMs have detection coverage for just 21% of MITRE ATT&CK techniques
Organizations ingest less than 15% of available security telemetry due to cost
More data. Less coverage. Higher costs.
This isn't a vendor problem. It's an architecture problem—and throwing more budget at it makes it worse.
Why Traditional Approaches Keep Failing
Approach 1: "We'll normalize it in the SIEM"
Reality: You're paying detection-tier pricing to do data engineering work. Custom parsers break when vendors change formats. Schema drift creates silent failures. Your analysts become parser maintenance engineers instead of threat hunters.
Approach 2: "We'll enrich at query time"
Reality: Queries become complex, slow, and expensive. Real-time detection suffers because correlation happens after the fact. Historical investigations become archaeology projects where analysts spend 60% of their time just finding relevant data.
Approach 3: "We'll train the AI on our data patterns"
Reality: You're training the AI to work around your data problems instead of fixing them. Every new data source requires retraining. The AI learns your inconsistencies and confidently reproduces them. Garbage in, articulate garbage out.
None of these approaches solve the root cause: your data is fragmented before it ever reaches your analytics.
The Foundation That Makes Everything Else Work
The organizations seeing real results from AI security investments share one thing: they fixed the data layer first.
Not by adding more tools. By adding a unification layer between their sources and their analytics—a security data pipeline that:
1. Collects everything once Cloud logs, identity events, SaaS activity, endpoint telemetry—without custom integration work for each source. Pull-based for APIs, push-based for streaming, snapshot-based for inventories. Built-in resilience handles the reliability nightmares so your team doesn't.
2. Translates to a common language So jsmith in Active Directory, jsmith@company.com in Azure, John Smith in Salesforce, and U04ABCD1234 in Slack all resolve to the same verified identity—automatically, at ingestion, not at query time.
3. Routes by value, not by volume High-fidelity security signals go to real-time detection. Compliance logs go to cost-effective storage. Noise gets filtered before it costs you money. Your SIEM becomes a detection engine, not an expensive data warehouse.
4. Preserves context for investigation The relationships between who, what, when, and where that investigations actually need—maintained from source to analyst to AI.
What This Looks Like in Practice
The 70% reduction in SIEM-bound data isn't about losing visibility—it's about not paying detection-tier pricing for compliance-tier logs.
More importantly: when your AI says "this user accessed these resources from this location," you can trust it—because every data point resolves to the same verified identity.
The Strategic Question for Security Leaders
Every organization will eventually build AI into their security operations. The question is whether that AI will be working with unified, trustworthy data—or fighting the same fragmentation that's already limiting your human analysts.
The SOC of the future isn't defined by which AI you choose. It's defined by whether your data architecture can support any AI you choose.
Questions to Ask Before Your Next Security Investment
Before you sign another security contract, ask these questions:
For your current stack:
"Can we trace a single identity across cloud, SaaS, and endpoint in under 60 seconds?"
"How long does it take to onboard a new log source end-to-end?"
For prospective vendors:
"Do you normalize to open standards like OCSF, or proprietary schemas?"
"How do you handle entity resolution across identity providers?"
"What routing flexibility do we have for cost optimization?"
"Does this add to our data fragmentation, or help resolve it?"
If your team hesitates on the first set, or vendors look confused by the second—you've found your actual problem.
The foundation comes first. Everything else follows.
Stay tuned to the next article on recommendations for architecture of the AI-enabled SOC
What's your experience? Are your AI security tools delivering on their promise, or hitting data quality walls? I'd love to hear what's working (or not) in the comments.
The managed security services market isn’t struggling with demand. Quite the opposite. As attack surfaces sprawl across cloud, SaaS, endpoints, identities, and operational systems, businesses are leaning more heavily than ever on MSSPs to deliver security outcomes they can’t realistically build in-house.
But that demand brings a different kind of pressure – customers aren’t buying coverage anymore. They’re looking to pay for confidence and reassurance: full visibility, consistent control, and the operational maturity to handle complexity, detect attacks, and find gaps to avoid unpleasant surprises. For MSSP leaders, trust has become the real product.
That trust isn’t easy to deliver. MSSPs today are running on deeply manual, repetitive workflows: onboarding new customers source by source, building pipelines and normalizing telemetry tool by tool, and expending precious engineering bandwidth on moving and managing security data that doesn’t meaningfully differentiate the service. Too much of their expertise is consumed in mechanics that are critical, but not meaningful.
The result is a barrier to scale. Not because MSSPs lack customers or talent, but because their operating model forces highly skilled teams to solve the same data problems over and over again. And that constraint shows up early. The first impression of an MSSP for a customer is overshadowed by the onboarding experience, when their services and professionalism are tested in tangible ways beyond pitches and promises. The speed and confidence with which an MSSP can move to complete, production-grade security visibility becomes the most lasting measure of their quality and effectiveness.
Industry analysis from firms such as D3 Security points to an inevitable consolidation in the MSSP market. Not every provider will scale successfully. The MSSPs that do will be those that expand efficiently, turning operational discipline into a competitive advantage. Efficiency is no longer a back-office metric; it’s a market differentiator.
That reality shows up early in the customer lifecycle most visibly, during onboarding. Long before detection accuracy or response workflows are evaluated, a more basic question is answered. How quickly can an MSSP move from a signed contract to reliable, production-grade security telemetry? Increasingly, the answer determines customer confidence, margin structure, and long-term competitiveness.
The Structural Mismatch: Multi-Customer Services and Manual Onboarding
MSSPs operate as professional services organizations, delivering security operations across many customer environments simultaneously. Each environment must remain strictly isolated, with clear boundaries around data access, routing, and policy enforcement. At the same time, MSSP teams require centralized visibility and control to operate efficiently.
In practice, many MSSPs still onboard each new customer as a largely independent effort. Much of the same data engineering and configuration work is repeated across customers, with small but critical variations. Common tasks include:
Manual configuration of data sources and collectors
Custom parsing and normalization of customer telemetry
Customer-specific routing and policy setup
Iterative tuning and validation before data is considered usable
This creates a structural mismatch. The same sources appear again and again, but the way those sources must be governed, enriched, and analyzed differs for each customer. As customer counts grow, repeated investment of engineering time becomes a significant efficiency bottleneck.
Senior engineers are often pulled into onboarding work that combines familiar pipeline mechanics with customer-specific policies and downstream requirements. Over time, this leads to longer deployment cycles, greater reliance on scarce expertise, and increasing operational drag.
This is not a failure of tools or talent. Skilled engineers and capable platforms can solve individual onboarding problems. The issue lies in the onboarding model itself. When knowledge exists primarily in ad-hoc engineering work, scripts, and tribal knowledge, it cannot be reused effectively at scale.
Why Onboarding Has Become a Bottleneck
At small scales, the inefficiency is tolerable. As MSSPs aim to scale, it becomes a growth constraint.
As MSSPs grow, onboarding must balance two competing demands:
Consistency, to ensure operational reliability across multiple customers; and
Customization, to respect each customer’s unique telemetry, data governance, and security posture.
Treating every environment identically introduces risk and compliance gaps. But customizing every pipeline manually introduces inefficiency and drag. This trade-off is what now defines the onboarding challenge for MSSPs.
Consider two customers using similar toolsets. One may require granular visibility into transactional data for fraud detection; the other may prioritize OT telemetry to monitor industrial systems. The mechanics of ingesting and moving data are similar, yet the way that data is treated — its routing, enrichment, retention, and analysis — differs significantly. Traditional onboarding models rebuild these pipelines repeatedly from scratch, multiplying engineering effort without creating reusable value.
The bottleneck is not the customization itself but the manual delivery of that customization. Scaling onboarding efficiently requires separating what must remain bespoke from what can be standardized and reused.
From Custom Setup to Systemized Onboarding
Incremental optimizations help only at the margins. Adding engineers, improving runbooks, or standardizing steps does not change the underlying dynamic. The same contextual work is still repeated for each customer.
The reason is that onboarding combines two fundamentally different kinds of work.
First, there is data movement. This includes setting up agents or collectors, establishing secure connections, and ensuring telemetry flows reliably. Across customers, much of this work is familiar and repeatable.
Second, there is data treatment. This includes policies, routing, enrichment, and detection logic. This is where differentiation and customer value are created.
When these two layers are handled together, MSSPs repeatedly rebuild similar pipelines for each customer. When handled separately, the model becomes scalable. The “data movement” layer becomes a standardized, automated process, while “customization” becomes a policy layer that can be defined, validated, and applied through governed configuration.
This approach allows MSSPs to maintain isolation and compliance while drastically reducing repetitive engineering work. It shifts human expertise upstream—toward defining intent and validating outcomes rather than executing low-level setup tasks.
In other words, systemized onboarding transforms onboarding from an engineering exercise into an operational discipline.
Applying AI to Onboarding Without Losing Control
Once onboarding is reframed in this way, AI can be applied effectively and responsibly.
AI-driven configuration observes incoming telemetry, identifies source characteristics, and recognizes familiar ingestion patterns. Based on this analysis, it generates configuration templates that define how pipelines should be set up for a given source type. These templates cover deployment, parsing, normalization, and baseline governance.
Importantly, this approach does not eliminate human oversight. Engineers review and approve configuration intent before it is executed. Automation handles execution consistently, while human expertise focuses on defining and validating how data should be treated.
Platforms such as Databahn support a modular pipeline model. Telemetry is ingested, parsed, and normalized once. Downstream treatment varies by destination and use case. The same data stream can be routed to a SIEM with security-focused enrichment and to analytics platforms with different schemas or retention policies, without standing up entirely new pipelines.
This modularity preserves customer-specific outcomes while reducing repetitive engineering work.
Reducing Onboarding Time by 90%
When onboarding is systemized and supported by AI-driven configuration, the reduction in time is structural rather than incremental.
AI-generated templates eliminate the need to start from a blank configuration for each customer. Parsing logic, routing rules, enrichment paths, and isolation policies no longer need to be recreated repeatedly. MSSPs begin onboarding with a validated baseline that reflects how similar data sources have already been deployed.
Automated configuration compresses execution time further. Once intent is approved, pipelines can be deployed through controlled actions rather than step-by-step manual processes. Validation and monitoring are integrated into the workflow, reducing handoffs and troubleshooting cycles.
In practice, this approach has resulted in onboarding time reductions of up to 90 percent for common data sources. What once required weeks of coordinated effort can be reduced to minutes or hours, without sacrificing oversight, security, or compliance.
What This Unlocks for MSSPs
Faster onboarding is only one outcome. The broader advantage lies in how AI-driven configuration reshapes MSSP operations:
Reduced time-to-value: Security telemetry flows earlier, strengthening customer confidence and accelerating value realization.
Parallel onboarding: Multiple customers can be onboarded simultaneously without overextending engineering teams.
Knowledge capture and reuse: Institutional expertise becomes encoded in templates rather than isolated in individuals.
Predictable margins: Consistent onboarding effort allows costs to scale more efficiently with revenue.
Simplified expansion: Adding new telemetry types or destinations no longer creates operational variability.
Collectively, these benefits transform onboarding from an operational bottleneck into a competitive differentiator. MSSPs can scale with control, predictability, and confidence — qualities that increasingly define success in a consolidating market.
Onboarding as the Foundation for MSSP Scale
As the MSSP market matures, efficient scale has become as critical as detection quality or response capability. Expanding telemetry, diverse customer environments, and cost pressure require providers to rethink how their operations are structured.
In Databahn’s model, multi-customer support is achieved through a beacon architecture. Each customer operates in an isolated data plane, governed through centralized visibility and control. This model enables scale only when onboarding is predictable and consistent.
Manual, bespoke onboarding introduces friction and drift. Systemized, AI-driven onboarding turns the same multi-customer model into an advantage. New customers can be brought online quickly, policies can be enforced consistently, and isolation can be preserved without slowing operations.
By encoding operational knowledge into templates, applying it through governed automation, and maintaining centralized oversight, MSSPs can scale securely without sacrificing customization. The shift is not merely about speed — it’s about transforming onboarding into a strategic enabler of growth.
Conclusion
The MSSP market is evolving toward consolidation and maturity, where efficiency defines competitiveness as much as capability. The challenge is clear: onboarding new customers must become faster, more consistent, and less dependent on manual engineering effort.
AI-driven configuration provides the structural change required to meet that challenge. By separating repeatable data movement from customer-specific customization, and by automating the configuration of the former through intelligent templates, MSSPs can achieve both speed and precision at scale.
In this model, onboarding is no longer a friction point; it becomes the operational foundation that supports growth, consistency, and resilience in an increasingly demanding security landscape.
For most CIOs and SRE leaders, observability has grown into one of the most strategic layers of the technology stack. Cloud-native architectures depend on it, distributed systems demand it, and modern performance engineering is impossible without it. And yet, even as enterprises invest heavily in their platforms, pipelines, dashboards, and agents, the experience of achieving true observability feels harder than it should be.
Telemetry and observability systems have become harder to track and manage than ever before. Data flows, sources, and volumes shift and scale unpredictably. Different cloud containers and applications straddle different regions and systems, introducing new layers of complexity and chaos that enterprises never built these systems for.
In this environment, the traditional assumptions underpinning observability begin to break down. The tools are more capable than ever, but the architecture that feeds them has not kept pace. The result is a widening gap between what organizations expect observability to deliver and what their systems are actually capable of supporting.
Observability is no longer a tooling problem. It is a challenge to create future-forward infrastructure for observability.
The New Observability Mandate
The expectations for observability systems today are much higher than when those systems were first created. Modern organizations require observability solutions that are fast, adaptable, consistent across different environments, and increasingly enhanced by machine learning and automation. This change is not optional; it is the natural result of how software has developed.
Distributed systems produce distributed telemetry. Every service, node, pod, function, and proxy contributes its own signals: traces, logs, metrics, events, and metadata form overlapping but incomplete views of the truth. Observability platforms strive to provide teams with a unified view, but they often inherit data that is inconsistent or poorly structured. The responsibility to interpret the data shifts downstream, and the platform becomes the place where confusion builds up.
Meanwhile, telemetry volume is increasing rapidly. Most organizations collect data much faster than they can analyze it. Costs rise with data ingestion and storage, not with gaining insights. Usually, only a small part of the collected telemetry is used for investigations or analytics, even though teams feel the need to keep collecting it. What was meant to improve visibility now overwhelms the very clarity it aimed to provide.
Finally, observability must advance from basic instrumentation to something smarter. Modern systems are too complex for human operators to interpret manually. Teams need observability that helps answer not just “what happened,” but “why it happened” and “what matters right now.” That transition requires a deeper understanding of telemetry at the data level, not just more dashboards or alerts.
These pressures lead to a clear conclusion. Observability requires a new architectural foundation that considers data as the primary product, not just a byproduct.
Why Observability Architectures are Cracking
When you step back and examine how observability stacks developed, a clear pattern emerges. Most organizations did not intentionally design observability systems; they built them up over time. Different teams adopted tools for tracing, metrics, logging, and infrastructure monitoring. Gradually, these tools were linked together through pipelines, collectors, sidecars, and exporters. However, the architectural principles guiding these integrations often received less attention than the tools themselves.
This piecemeal evolution leads to fragmentation. Each tool has its own schema, enrichment model, and assumptions about what “normal” looks like. Logs tell one story, metrics tell another, and traces tell a third. Combining these views requires deep expertise and significant operational effort. In practice, the more tools an organization adds, the harder it becomes to maintain a clear picture of the system.
Silos are a natural result of this fragmentation, leading to many downstream issues. Visibility becomes inconsistent across teams, investigations slow down, and it becomes harder to identify, track, and understand correlations across different data types. Data engineers must manually translate and piece together telemetry contexts to gain deeper insights, which creates technical debt and causes friction for the modern enterprise observability team.
Cost becomes the next challenge. Telemetry volume increases predictably in cloud-native environments. Scaling generates more signals. More signals lead to increased data ingestion. Higher data ingestion results in higher costs. Without a structured approach to parsing, normalizing, and filtering data early in its lifecycle, organizations end up paying for unnecessary data processing and can't make effective use of the data they collect.
Complexity adds another layer. Traditional ingest pipelines weren't built for constantly changing schemas, high-cardinality workloads, or flexible infrastructure. Collectors struggle during burst periods. Parsers fail when fields change. Dashboards become unreliable. Teams rush to fix telemetry before they can fix the systems the telemetry is meant to monitor.
Even the architecture itself works against teams. Observability stacks were initially built for stable environments. They assume predictable data formats, slow-moving schemas, and a manageable number of sources. Modern environments break each of these assumptions.
And beneath it all lies a deeper issue: telemetry is often gathered before it is fully understood. Downstream tools receive raw, inconsistent, and noisy data, and are expected to interpret it afterward. This leads to a growing insight gap. Organizations collect more information than ever, but insights do not keep up at the same rate.
The Architectural Root Cause
Observability systems were built around tools rather than a unified data model. The architecture expanded through incremental additions instead of being designed from first principles. The growing number of tools, along with the increased complexity and scale of telemetry, created systemic challenges. Engineers now spend more time tracking, maintaining, and repairing data pipelines than developing systems to enhance observability. The unexpected surge in complexity and volume overwhelmed existing systems, which had been improved gradually. Today, Data Engineers inherit legacy systems with fragmented and complex tools and pipelines, requiring more time to manage and maintain, leaving less time to improve observability and more on fixing it.
A modern observability system must be designed to overcome these brittle foundations. To achieve adaptive, cost-efficient observability that supports AI-driven analysis, organizations need to treat telemetry as a structured, governed, high-integrity layer. Not as a byproduct that downstream tools must interpret and repair.
The Shift Upstream: Intelligence in the Pipeline
Observability needs to begin earlier in the data lifecycle. Instead of pushing raw telemetry downstream, teams should reshape, enrich, normalize, and optimize data while it is still in motion. This single shift resolves many of the systemic issues that plague observability systems today.
AI-powered parsing and normalization ensure telemetry is consistent before reaching a tool. Automated mapping reduces the operational effort of maintaining thousands of fields across numerous sources. If schemas change, AI detects the update and adjusts accordingly. What used to cause issues becomes something AI can automatically resolve.
The analogy is straightforward: tracking, counting, analyzing, and understanding data in pipelines while it is streaming is easier than doing so when it is stationary. Volumes and patterns can be identified and monitored more effortlessly within the pipeline itself as the data enters the system, providing the data stack with a better opportunity to comprehend them and direct them to the appropriate destination.
Data engineering automation enhances stability. Instead of manually built transformations that fail silently or decline in quality over time, the pipeline becomes flexible. It can adapt to new event types, formats, and service boundaries. The platform grows with the environment rather than being disrupted by it.
Upstream visibility adds an extra layer of resilience. Observability should reveal not only how the system behaves but also the health of the telemetry that describes it. If collectors fail, sources become noisy, fields drift, or events spike unexpectedly, teams need to know at the source. Troubleshooting starts before downstream tools are impacted.
Intelligent data tiering is only possible when data is understood early. Not every signal warrants the same storage cost or retention period. By assessing data based on relevance rather than just time, organizations can significantly reduce costs while maintaining high-signal visibility.
All of this contributes to a fundamentally different view of observability. It is no longer something that happens in dashboards. It occurs in the pipeline.
By managing telemetry as a governed, intelligent foundation, organizations achieve clearer visibility, enhanced control, and a stronger base for AI-driven operations.
How Databahn Supports this Architectural Future
In the context of these structural issues shaping the future of observability, it is essential to note that AI-powered pipelines can be the right platform for enterprises to build this next-generation foundation – today, and not as part of an aspirational future.
Databahn provides the upstream intelligence described above by offering AI-powered parsing, normalization, and enrichment that prepare telemetry before it reaches downstream systems. The platform automates data engineering workflows, adjusts to schema drift, offers detailed visibility into source telemetry, and supports intelligent data tiering based on value, not volume. The result is an AI-ready telemetry fabric that enhances the entire observability stack, regardless of the tools an organization uses.
Instead of adding yet another system to an already crowded ecosystem, Databahn helps organizations modernize the architecture layer underneath their existing tools. This results in a more cohesive, resilient, and cost-effective observability foundation.
The Path Forward: AI-Ready Telemetry Infrastructure
The future of observability won't be shaped by more dashboards or agents. Instead, it depends on whether organizations can create a stable, adaptable, and intelligent foundation beneath their tools.
That foundation starts with telemetry. It needs structure, consistency, relevance, and context. It demands automation that adapts as systems change. It also requires data that is prepared for AI reasoning.
Observability should move from being tool-focused to data-focused. Only then can teams gain the clarity, predictability, and intelligence needed in modern, distributed environments.
This architectural shift isn't a future goal; it's already happening. Teams that adopt it will have a clear edge in cost, resilience, and speed.
Every industry goes through moments of clarity, moments when someone steps back far enough to see not just the technologies taking shape, but the forces shaping them. The Software Analyst Cybersecurity Research (SACR) team’s latest report on Security Data Pipeline Platforms (SDPP) is one of those moments. It is rare for research to capture both the energy and the tension inside a rapidly evolving space, and to do so with enough depth that vendors, customers, and analysts all feel seen. Their work does precisely that.
Themes from the Report
Several themes stood out to us at Databahn because they reflect what we hear from customers every day. One of those themes is the growing role of AI in security operations. SACR is correct in noting that AI is no longer just an accessory. It is becoming essential to how analysts triage, how detections are created, and how enterprises assess risk. For AI to work effectively, it needs consistent, governed, high-quality data, and the pipeline is the only place where that foundation can be maintained.
Another theme is the importance of visibility and monitoring throughout the pipeline. As telemetry expands across cloud, identity, OT, applications, and infrastructure, the pipeline has become a dynamic system rather than just a simple conduit. SOC teams can no longer afford blind spots in how their data flows, what is breaking upstream, or how schema changes ripple downstream. SACR’s recognition of this shift reflects what we have observed in many large-scale deployments.
Resilience is also a key theme in the report. Modern security architecture is multi-cloud, multi-SIEM, multi-lake, and multi-tool. It is distributed, dynamic, and often unpredictable. Pipelines that cannot handle drift, bursts, outages, or upstream failures simply cannot serve the SOC. Infrastructure must be able to gracefully degrade and reliably recover. This is not just a feature; it is an expectation.
Finally, SACR recognizes something that is becoming harder for vendors to admit: the importance of vendor neutrality. Neutrality is more than just an architectural choice; it’s the foundation that enables enterprises to choose the right SIEM for their needs, the right lake for their scale, the right detection strategy for their teams, and the right AI platforms for their maturity. A control plane that isn’t neutral eventually becomes a bottleneck. SACR’s acknowledgment of this risk demonstrates both insight and courage.
The future of the SOC has room for AI, requires deep visibility, depends on resilience, and can only remain healthy if neutrality is preserved. Another trend that SACR’s report tracked was the addition of adjacent functions, bucketed as ‘SDP Plus’, which covered a variety of features – adding storage options, driving some detections in the pipeline directly, and observability, among others. The report has cited Databahn for their ‘pipeline-centric’ strategy and our neutral positioning.
As the report captures what the market is doing, it invites each of us to think more deeply about why the market is doing it and whether that direction serves the long-term interests of the SOC.
The SDP Plus Drift
Pipelines that started with clear purpose have expanded outward. They added storage. They added lightweight detection. They added analytics. They built dashboards. They released thin AI layers that sat beside, rather than inside, the data. In most cases, these were not responses to customer requests. They were responses to a deeper tension, which is that pipelines, by their nature, are quiet. A well-built pipeline disappears into the background. When a category is young, vendors fear that silence. They fear being misunderstood. And so they begin to decorate the pipeline with features to make it feel more visible, more marketable, more platform-like.
It is easy to understand why this happens. It is also easy to see why it is a problem.
A data pipeline has one essential purpose. It moves and transforms data so that every system around it becomes better. That is the backbone of its value. When a pipeline begins offering storage, it creates a new gravity center inside the enterprise. When it begins offering detection, it creates a new rule engine that the SOC must tune and maintain. When it adds analytics, it introduces a new interpretation layer that can conflict with existing sources of truth. None of these actions are neutral. Each shifts the role of the pipeline from connector to competitor.
This shift matters because it undermines the very trust that pipelines rely on. It is similar to choosing a surgeon. You choose them for their precision, their judgment, their mastery of a single craft. If they try to win you over by offering chocolates after the surgery, you might appreciate the gesture, but you will also question the focus. Not because chocolates are bad, but because that is not why you walked into the operating room.
Pipelines must not become distracted. Their value comes from the depth of their craft, not the breadth of their menu. This is why it is helpful to think about security data pipelines as infrastructure. Infrastructure succeeds when it operates with clarity. Kubernetes did not attempt to become an observability tool. Snowflake did not attempt to become a CRM. Okta did not attempt to become a SIEM. What made them foundational was their refusal to drift. They became exceptional by narrowing their scope, not widening it. Infrastructure is at its strongest when it is uncompromising in its purpose.
Security data pipelines require the same discipline. They are not just tools; they are the foundation. They are not designed to interpret data; they are meant to enhance the systems that do. They are not intended to detect threats; they are meant to ensure those threats can be identified downstream with accuracy. They do not own the data; they are responsible for safeguarding, normalizing, enriching, and delivering that data with integrity, consistency, and trust.
The Value of SDPP Neutrality
Neutrality becomes essential in this situation. A pipeline that starts to shift toward analytics, storage, or detection will eventually face a choice between what's best for the customer and what's best for its own growing platform. This isn't just a theoretical issue; it's a natural outcome of economic forces. Once you sell a storage layer, you're motivated to route more data into it. Once you sell a detection layer, you're motivated to optimize the pipeline to support your detections. Neutrality doesn't vanish with a single decision; it gradually erodes through small compromises.
At Databahn, neutrality isn't optional; it's the core of our architecture. We don’t compete with the SIEM, data lake, detection systems, or analytics platforms. Instead, our role is to support them. Our goal is to provide every downstream system with the cleanest, most consistent, most reliable, and most AI-ready data possible. Our guiding principle has always been straightforward: if we are infrastructure, then we owe our customers our best effort, not our broadest offerings.
This is why we built Cruz as an agentic AI within the pipeline, because AI that understands lineage, context, and schema drift is far more powerful than AI that sits on top of inconsistent data. This is why we built Reef as an insight layer, not as an analytics engine, because the value lies in illuminating the data, not in competing with the tools that interpret it. Every decision has stemmed from a belief that infrastructure should deepen, not widen, its expertise.
We are entering an era in cybersecurity where clarity matters more than ever. AI is accelerating the complexity of the SOC. Enterprises are capturing more telemetry than at any point in history. The risk landscape is shifting constantly. In moments like these, it is tempting to expand in every direction at once. But the future will not be built by those who try to be everything. It will be built by those who know exactly what they are, and who focus their energy on becoming exceptional at that role.
Closing thoughts
The SACR report highlights how far the category has advanced. I hope it also serves as a reminder of what still needs attention. If pipelines are the control plane of the SOC, then they must stay pure. If they are infrastructure, they must be built with discipline. If they are neutral, they must remain so. And if they are as vital to the future of AI-driven security as we believe, they must form the foundation, not just be a feature.
At Databahn, we believe the most effective pipeline stays true to its purpose. It is intelligent, reliable, neutral, and deeply focused. It does not compete with surrounding systems but elevates them. It remains committed to its craft and doubles down on it. By building with this focus, the future SOC will finally have an infrastructure layer worthy of the intelligence it supports.
Get expert updates on AI-powered data management, security, and automation—straight to your inbox
Featured Authors
No items found.
By clicking "Accept", you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.



.png)

.png)


.png)
.png)

.png)



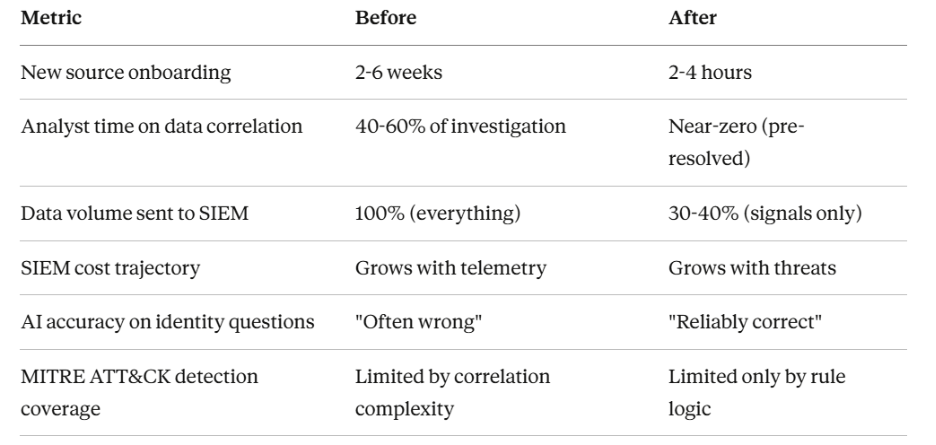



.avif)
.avif)

