.avif)


In many enterprises today, a wealth of security telemetry sits locked away in engineering-centric systems. Only the SIEM engineers or data teams can directly query raw logs, leaving other stakeholders waiting in line for reports or context. Bringing security data to business users – whether they are threat hunters, compliance auditors, or CISOs needing quick insights – can dramatically improve decision-making. But unlocking data access broadly isn’t as simple as opening the floodgates. It must be done without compromising data integrity, compliance, or cost. In this post, we explore how security and IT organizations can democratize analytics and make telemetry accessible beyond just engineers, all while enforcing quality guardrails and governance.
The Challenge: Data Silos and Hidden Telemetry
Despite collecting more security data than ever, organizations often struggle to make it useful beyond a few expert users. Several barriers block broader access:
- Data Silos: Logs and telemetry are fragmented across SIEMs, data lakes, cloud platforms, and individual tools. Different teams “own” different data, and there’s no unified view. Siloed data means business users can’t easily get a complete picture – they have to request data from various gatekeepers. This fragmentation has grown as telemetry volume explodes ~30% annually, doubling roughly every three years. The result is skyrocketing costs and blind spots in visibility.
- Lack of Context and Consistency: Raw logs are cryptic and inconsistent. Each source (firewalls, endpoints, cloud apps) emits data in its own format. Without normalization or enrichment, a non-engineer cannot readily interpret, correlate, or use the data. Indeed, surveys suggest fewer than 40% of collected logs provide real investigative value – the rest is noise or duplicated information that clutters analysis.
- Manual Normalization & Integration Effort: Today, integrating a new data source or making data useable often requires painful manual mapping and cleaning. Teams wrangle with field name mismatches and inconsistent schemas. This slows down onboarding of new telemetry – some organizations report that adding new log sources is slow and resource-intensive due to normalization burdens and SIEM license limits. The result is delays (weeks or months) before business users or new teams can actually leverage fresh data.
- Cost and Compliance Fears: Opening access broadly can trigger concerns about cost overruns or compliance violations. Traditional SIEM pricing models charge per byte ingested, so sharing more data with more users often meant paying more or straining licenses. It’s not uncommon for SIEM bills to run into millions of dollars. To cope, some SOCs turn off “noisy” data sources (like detailed firewall or DNS logs) to save money. This trade-off leaves dangerous visibility gaps. Furthermore, letting many users access sensitive telemetry raises compliance questions: could someone see regulated personal data they shouldn’t? Could copies of data sprawl in unsecured areas? These worries make leaders reluctant to fully democratize access.
In short, security data often remains an engineer’s asset, not an enterprise asset. But the cost of this status quo is high: valuable insights stay trapped, analysts waste time on data plumbing rather than hunting threats, and decisions get made with partial information. The good news is that forward-thinking teams are realizing it doesn’t have to be this way.
Why Broader Access Matters for Security Teams
Enabling a wider range of internal users to access telemetry and security data – with proper controls – can significantly enhance security operations and business outcomes:
- Faster, Deeper Threat Hunting: When seasoned analysts and threat hunters (even those outside the core engineering team) can freely explore high-quality log data, they uncover patterns and threats that canned dashboards miss. Democratized access means hunts aren’t bottlenecked by data engineering tasks – hunters spend their time investigating, not waiting for data. Organizations using modern pipelines report 40% faster threat detection and response on average, simply because analysts aren’t drowning in irrelevant alerts or struggling to retrieve data.
- Audit Readiness & Compliance Reporting: Compliance and audit teams often need to sift through historical logs to demonstrate controls (e.g. proving that every access to a payroll system was logged and reviewed). Giving these teams controlled access to structured telemetry can cut weeks off audit preparation. Instead of ad-hoc data pulls, auditors can self-serve standardized reports. This is crucial as data retention requirements grow – many enterprises must retain logs for a year or more. With democratized data (and the right guardrails), fulfilling an auditor’s request becomes a quick query, not a fire drill.
- Informed Executive Decision-Making: CISOs and business leaders are increasingly data-driven. They want metrics like “How many high-severity alerts did we triage last quarter?”, “Where are our visibility gaps?”, or “What’s our log volume trend and cost projection?” on demand. If security data is readily accessible and comprehensible (not just locked in engineering tools), executives can get these answers in hours instead of waiting for a monthly report. This leads to more agile strategy adjustments – for example, reallocating budget based on real telemetry usage or quickly justifying investments by showing how data volumes (and thus SIEM costs) are trending upward 18%+ year-over-year.
- Collaboration Across Teams: Security issues touch many parts of the business. Fraud teams might want to analyze login telemetry; IT ops teams might need security event data to troubleshoot outages. Democratized data – delivered in a consistent, easy-to-query form – becomes a lingua franca across teams. Everyone speaks from the same data, reducing miscommunication. It also empowers “citizen analysts” in various departments to run their own queries (within permitted bounds), alleviating burden on the central engineering team.
In essence, making security telemetry accessible beyond engineers turns data into a strategic asset. It ensures that those who need insights can get them, and it fosters a culture where decisions are based on evidence from real security data. However, to achieve this utopia, we must address the very real concerns around quality, governance, and cost.
Breaking Barriers with a Security Data Pipeline Approach
How can organizations enable broad data access without creating chaos? The answer lies in building a foundation that prepares and governs telemetry at the data layer – often called a security data pipeline or security data fabric. Platforms like Databahn’s take the approach of sitting between sources and users (or tools), automatically handling the heavy lifting of data engineering so that business users get clean, relevant, and compliant data by default. Key capabilities include:
- Automated Parsing and Normalization: A modern pipeline will auto-parse logs and align them to a common schema or data model (such as OCSF or CIM) as they stream in. This eliminates the manual mapping for each new source. For example, whether an event came from AWS or an on-prem firewall, the pipeline can normalize fields (IP addresses, user IDs, timestamps) into a consistent structure. Smart normalization ensures data is usable out-of-the-box by any analyst or tool. It also means if schemas change unexpectedly, the system detects it and adjusts – preventing downstream breakages. (In fact, schema drift tracking is a built-in feature: the pipeline flags if a log format changes or new fields appear, preserving consistency.)
- Contextual Enrichment: To make data meaningful to a broader audience, pipelines enrich raw events with context before they reach users. This might include adding asset details (hostname, owner), geolocation for IPs, or tagging events with a MITRE ATT&CK technique. By inserting context at ingestion, the data presented to a business user is more self-explanatory and useful. Enrichment also boosts detection. For instance, adding threat intelligence or user role info to logs gives analysts richer information to spot malicious activity. All of this happens automatically in an intelligent data pipeline, rather than through ad-hoc scripts after the fact.
- Unified Telemetry Repository: Instead of scattering data across silos, a security data fabric centralizes collection and routing. Think of it as one pipeline feeding multiple destinations – SIEM, data lake, analytics tools – based on need. This unification breaks down silos and ensures everyone is working from the same high-quality data. It also decouples data from any single tool. Teams can query telemetry directly in the pipeline’s data store or a lake, without always going through the SIEM UI. This eliminates vendor lock-in and gives business users flexible access to data without needing proprietary query languages.
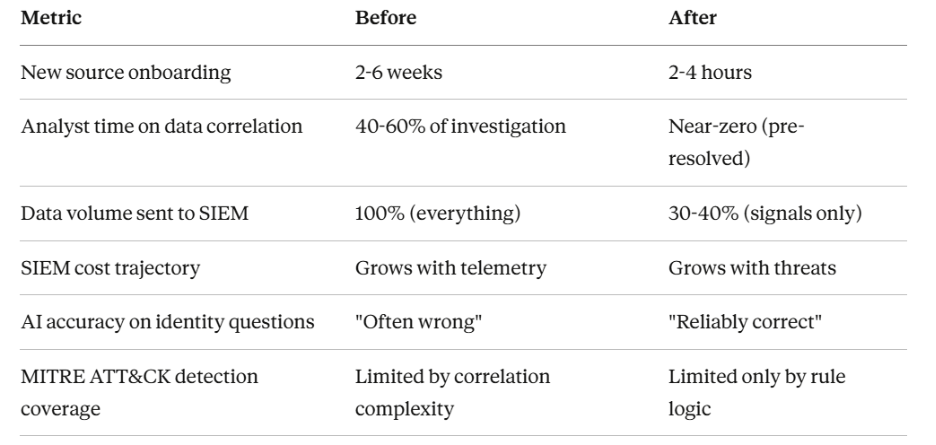
- Prebuilt Filtering & Volume Reduction: A critical guardrail for both cost and noise control is the ability to filter out low-value data before it hits expensive storage. Advanced pipelines come with libraries of rules (and AI models) to automatically drop or down sample verbose events like heartbeats, debug logs, or duplicates. In practice, organizations can reduce log volumes by 45% or more using out-of-the-box filters, and customize rules further for their environment. This volume control is transformative: it cuts costs and makes data sets leaner for business users to analyze. For example, one company achieved a 60% reduction in log volume within 2 weeks, which saved about $300,000 per year in SIEM licensing and another $50,000 in storage costs by eliminating redundant data. Volume reduction not only slashes bills; it also means users aren’t wading through oceans of noise to find meaningful signals.
- Telemetry Health and Lineage Tracking: To safely open data access, you need confidence in data integrity. Leading platforms provide end-to-end observability of the data pipeline – every event is tracked from ingestion to delivery. This includes monitoring source health: if a data source stops sending logs or significantly drops in volume, the system raises a silent source alert. These silent device or source alerts ensure that business users aren’t unknowingly analyzing stale data; the team will know immediately if, say, a critical sensor went dark. Pipelines also perform data quality checks (flagging malformed records, missing fields, or time sync issues) to maintain a high-integrity dataset. A comprehensive data lineage is recorded for compliance, one can audit exactly how an event moved and was transformed through the pipeline. This builds trust in the data. When a compliance officer queries logs, they have assurance of the chain of custody and that all data is accounted for.
- Governance and Security Controls: A “democratized” data platform must still enforce who can see what. Modern security data fabrics integrate with role-based access control and masking policies. For instance, one can mask sensitive fields (like PII) on certain data for general business users, while allowing authorized investigators to see full details. They also support data tiering – keeping critical, frequently used data in a hot, quickly accessible store, while archiving less-used data to cheaper storage. This ensures cost-effective compliance: everything is retained as needed, but not everything burdens your high-performance tier. In practice, such tiering and routing can reduce SIEM ingestion footprints by 50% or more without losing any data. Crucially, governance features mean you can open up access confidently and every user’s access can be scoped with every query is logged.
By implementing these capabilities, security and IT organizations turn their telemetry into a well-governed, self-service analytics layer. The effect is dramatic. Teams that have adopted security data pipeline platforms see outcomes like: 70–80% less data volume (with no loss of signal), 50%+ lower SIEM costs, and far faster onboarding of new data sources. In one case, a financial firm was able to onboard new logs 70% faster and cut $390K from annual SIEM spend after deploying an intelligent pipeline. Another enterprise shrunk its daily ingest by 80%, saving roughly $295K per year on SIEM licensing. These real-world gains show that simplifying and controlling data upstream has both operational and financial rewards.
The Importance of Quality and Guardrails
While “data democratization” is a worthy goal, it must be paired with strong guardrails. Free access to bad or uncontrolled data helps no one. To responsibly broaden data access, consider these critical safeguards (baked into the platform or process):
- Data Quality Validation: Ensure that only high-quality, parsed and complete data is presented to end users. Automated checks should catch corrupt logs, enforce schema standards, and flag anomalies. For example, if a log source starts spitting out gibberish due to a bug, the pipeline can quarantine those events. Quality issues that might go unnoticed in a manual process (or be discovered much later in analysis) are surfaced early. High-quality, normalized telemetry means business users trust the data – they’re more likely to use data if they aren’t constantly encountering errors or inconsistencies.
- Schema Drift Detection: As mentioned, if a data source changes its format or a new log type appears, it can silently break queries and dashboards. A guardrail here is automated drift detection: the moment an unexpected field or format shows up, the system alerts and can even adapt mappings. This proactive approach prevents downstream users from being blindsided by missing or misaligned data. It’s akin to having an early warning system for data changes. Keeping schemas consistent is vital for long-term democratization, because it ensures today’s reports remain accurate tomorrow.
- Silent Source (Noisy Device) Alerts: If a critical log source stops reporting (or significantly drops in volume), that’s a silent failure that could skew analyses. Modern telemetry governance includes monitoring each source’s heartbeat. If a source goes quiet beyond a threshold, it triggers an alert. For instance, if an important application’s logs have ceased, the SOC knows immediately and can investigate or inform users that data might be incomplete. This guardrail prevents false confidence in data completeness.
- Lineage and Audit Trails: With more users accessing data, you need an audit trail of who accessed what and how data has been transformed. Comprehensive lineage and audit logging ensures that any question of data usage can be answered. For compliance reporting, you can demonstrate exactly how an event flowed from ingestion to a report – satisfying regulators that data is handled properly. Lineage also helps debugging: if a user finds an odd data point, engineers can trace its origin and transformations to validate it.
- Security and Privacy Controls: Data democratization should not equate to free-for-all access. Implement role-based access so that users only see data relevant to their role or region. Use tokenization or masking for sensitive fields. For example, an analyst might see a user’s ID but not their full personal details unless authorized. Also, leverage encryption and strong authentication on the platform holding this telemetry. Essentially, treat your internal data platform with the same rigor as a production system – because it is one. This way, you reap the benefits of open access safely, without violating privacy or compliance rules.
- Cost Governance (Tiering & Retention): Finally, keep cost optics in check by tiering data and setting retention appropriate to each data type. Not all logs need 1-year expensive retention in the SIEM. A governance policy might keep 30 days of high-signal data in the SIEM, send three months of medium-tier data to a cloud data lake, and archive a year or more in cold storage. Users should still be able to query across these tiers (transparently if possible), but the organization isn’t paying top dollar for every byte. As noted earlier, enterprises that aggressively tier and filter data can cut their hot storage footprints by at least half. That means democratization doesn’t blow up the budget – it optimizes it by aligning spend with value.
With these guardrails in place, opening up data access is no longer a risky proposition. It becomes a managed process of empowering users while maintaining control. Think of it like opening more lanes on a highway but also adding speed limits, guardrails, and clear signage – you get more traffic flow, safely.
Conclusion: Responsible Data Democratization – What to Prioritize
Expanding access to security telemetry unlocks meaningful operational value, but it requires structured execution. Begin by defining a common schema and governance process to maintain data consistency. Strengthen upstream data engineering so telemetry arrives parsed, enriched, and normalized, reducing manual overhead and improving analyst readiness. Use data tiering and routing to control storage costs and optimize performance across SIEM, data lakes, and downstream analytics.
Treat the pipeline as a product with full observability, ensuring issues in data flow or parsing are identified early. Apply role-based access controls and privacy safeguards to balance accessibility with compliance requirements. Finally, invest in user training and provide standardized queries and dashboards so teams can derive insights responsibly and efficiently.
With these priorities in place, organizations can broaden access to security data while preserving integrity, governance, and cost-efficiency – enabling faster decisions and more effective threat detection across the enterprise.






.avif)





.avif)

.avif)







