


The Case for a Security Data Lake
Today’s business challenges require organizations to consume and store a vast quantity of raw security data in the form of logs, events, and datasets, as well as a substantial volume of security analytics information to support threat hunting and forensics. For some industries, there are regulatory and compliance requirements which also necessitate the storage of security data for extensive time periods. With organizations supporting a diverse set of users across geographies, managing multiple cloud-environments and on-premises networks, and supporting multiple devices – all while ensuring a centralized and cohesive security solution. In such cases, ensuring that all security data is collected and maintained in one accessible location is important. Enterprises are increasingly turning to security data lakes to perform this task.
Read how DataBahn helped a company forced to use 3 different SIEMs for data retention for compliance by giving them control of their own data DOWNLOAD
What is a Security Data Lake?
A security data lake is a central hub for storing, processing, and securing vast quantities of structured, unstructured, and semi-structured security-related data and information. By creating a specialized data repository for security data and threat intelligence, security data lakes enable organizations and their security teams to find, understand, and respond to cybersecurity threats more effectively.
Having a security data lake overcomes two distinct problems – security and access. IT and Security teams at organizations would want to ensure that their security data isn’t easily accessible and / or editable to ensure it isn’t modified or corrupted but ensure that it is quickly and easily accessible for SOCs for a faster MTTD / MTTR. Keeping all security-relevant data in a specific security data lake makes it easier for SOCs to access relevant logs and security information at a high velocity, while keeping it secure from malicious or unpermitted access.
How does a Security Data Lake work?
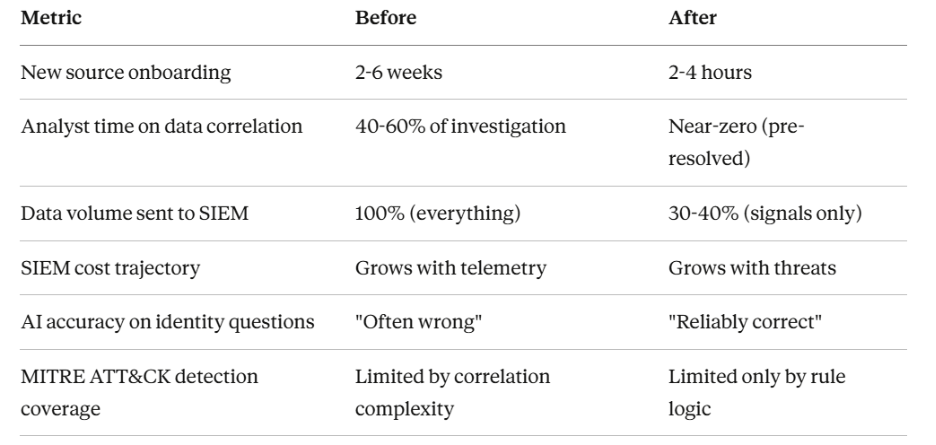
In traditional cybersecurity, legacy SIEMs were built to collect all security-related data from various sources in one place, and then analyze them by structuring the data into predefined schemas to flag anomalous patterns and identify potential threats through real-time analysis and examining historical data for patterns and trends. However, with the explosion in security data volume, legacy SIEMs struggled to identify relevant threats, while enterprises struggled with the ballooning SIEM costs.
Security Data Lakes emerged to solve this problem, becoming a scalable repository for all security data that could be connected to multiple cybersecurity tools so that threats could be identified, and incidents could be managed and documented easily. SOCs architect a network whereby security data is collected and ingested into the SIEM, and then stored in the Security Data Lake for analysis or threat hunting purposes.
Use cases of a Security Data Lake
- Easy and fast analysis of data across large time periods – including multiple years! – without needing to go to multiple sources due to the centralization of security data.
- Simplified compliance with easier monitoring and reporting on security data to ensure all relevant security data is stored and monitored for compliance purposes.
- Smarter and faster security investigations and threat hunting with centralized data to analyze, leading to improved MTTD and MTTR for security teams.
- Streamline access and security data management by optimizing accessibility and permissions for your security teams across hybrid environments.
Benefits of a Security Data Lake
As a centralized security data repository, there are numerous benefits to modern cybersecurity teams in leveraging a security data lake to manage and analyze security data. Here are some of the key advantages:
- Enhanced Visibility and Contextual Insights: Security Data Lakes allow organizations to seamlessly blend security data with business information that provides contextual value. This enables more informed assessments and quicker responses by providing greater visibility and deeper insights into potential threats for security teams.
- Cost-Effective Long-Term Storage: Security Data Lakes enable organizations to store large volumes of historical security data. This enables more effective threat hunting, helping cybersecurity teams identify anomalous behavior better and track incidents of concern without incurring very high SIEM licensing costs.
- Accelerated Incident Investigation: By supporting a high number of concurrent users and substantial computing resources, security data lakes facilitate rapid incident investigations to ensure faster detection and faster response. This enables security teams to deliver improved MTTD and MTTR.
- Advanced Security Analytics: Security Data Lakes provide a platform for advanced analytics capabilities, enabling collaboration between security and data science teams. This collaboration can lead to the development of sophisticated behavior models and machine learning analytics, enhancing the organization’s ability to detect and respond to threats.
- Scalability and Flexibility: As data volumes and attack surfaces grow, security data lakes offer the scalability needed to manage and analyze vast amounts of data, especially as the volume of security data continues to rise and becomes troublesome for SOCs to manage. Using a Security Data Lake makes it easier for organizations to collect security data from multiple sources across environments with ease.
- AI-Readiness for SOCs: Owning your own security data is critical for SOCs to integrate and adopt best-of-breed AI models to automate investigations and enhance data governance. Preparing aggregated security data for use in AI models and building applications and workflows that leverage AI to make SOCs more effective requires centralized data storage.
Read how DataBahn helped a company forced to use 3 different SIEMs for data retention for compliance by giving them control of their own data DOWNLOAD






.avif)





.avif)

.avif)







