


In cybersecurity today, the most precious resource is not the latest tool or threat feed – it is intelligence. And this intelligence is only as strong as the data foundation that creates it from the petabytes of security telemetry drowning enterprises today. Security operation centers (SOCs) worldwide are being asked to defend at AI speed, while still struggling to navigate a tidal wave of logs, redundant alerts, and fragmented systems.
This is less about a product release and more about a movement—a movement that places data at the foundation for agentic, AI-powered cybersecurity. It signals a shift in how the industry must think about security data: not as exhaust to be stored or queried, but as a living fabric that can be structured, enriched, and made ready for AI-native defense.
At DataBahn, we are proud to partner with Databricks and fully integrate with their technology. Together, we are helping enterprises transition from reactive log management to proactive security intelligence, transforming fragmented telemetry into trusted, actionable insights at scale.
From Data Overload to Data Intelligence
For decades, the industry’s instinct has been to capture more data. Every sensor, every cloud workload, and every application heartbeat is shipped to a SIEM or stored in a data lake for later investigation. The assumption was simple: more data equals better defense. But in practice, this approach has created more problems for enterprises.
Enterprises now face terabytes of daily data ingestion, much of which is repetitive, irrelevant, or misaligned with actual detection needs. This data also comes in different formats from hundreds and thousands of devices, and security tools and systems are overwhelmed by noise. Analysts are left searching for needles in haystacks, while adversaries increasingly leverage AI to strike more quickly and precisely.
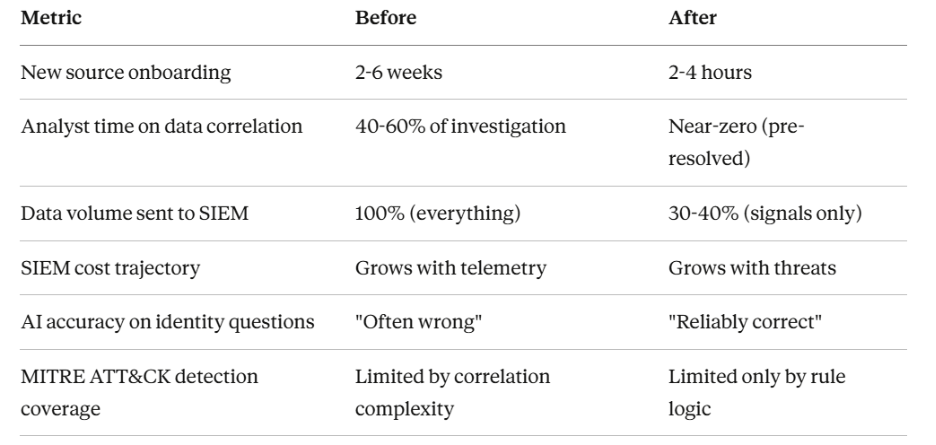
What’s needed is not just scale, but intelligence: the ability to collect vast volumes of security data and to understand, prioritize, analyze, and act on it while it is in motion. Databricks provides the scale and flexibility to unify massive volumes of telemetry. DataBahn brings the data collection, in-motion enrichment, and AI-powered tiering and segmenting that transform raw telemetry into actionable insights.
Next-Gen Security Data Infrastructure Platform
Databricks is the foundation for operationalizing AI at scale in modern cyber defense, enabling faster threat detection, investigation, and response. It enables the consolidation of all security, IT, and business data into a single, governed Data Intelligence Platform – which becomes a ready dataset for AI to operate on. When you combine this with DataBahn, you create an AI-ready data ecosystem that spans from source to destination and across the data lifecycle.
DataBahn sits on the left of Databricks, ensuring decoupled and flexible log and data ingestion into downstream SIEM solutions and Databricks. It leverages Agentic AI for data flows, automating the ingestion, parsing, normalization, enrichment, and schema drift handling of security telemetry across hundreds of formats. No more brittle connectors, no more manual rework when schemas drift. With AI-powered tagging, tracking, and tiering, you ensure that the correct data goes to the right place and optimize your SIEM license costs.
Agentic AI is leveraged to deliver insights and intelligence not just to data at rest, stored in Databricks, but also in flight via a persistent knowledge layer. Analysts can ask real questions in natural language and get contextual answers instantly, without writing queries or waiting on downstream indexes. Security tools and AI applications can access this layer to reduce time-to-insight and MTTR even more.
The solution brings the data intelligence vision tangible for security and is in sync with DataBahn’s vision for Headless Cyber Architecture. This is an ecosystem where enterprises control their own data in Databricks, and security tools (such as the SIEM) do less ingestion and more detection. Your Databricks security data storage becomes the source of truth.
Making the Vision Real for Enterprises
Security leaders don’t need another dashboard or more security tools. They need their teams to move faster and with confidence. For that, they need their data to be reliable, contextual, and usable – whether the task is threat hunting, compliance, or powering a new generation of AI-powered workflows.
By combining Databricks’ unified platform with DataBahn’s agentic AI pipeline, enterprises can:
- Cut through noise at the source: Filter out low-value telemetry before it ever clogs storage or analytics pipelines, preserving only what matters for detection and investigation.
- Enrich with context automatically: Map events against frameworks such as MITRE ATT&CK, tag sensitive data for governance, and unify signals across IT, cloud, and OT environments.
- Accelerate time to insight: Move away from waiting hours for query results to getting contextual answers in seconds, through natural language interaction with the data itself. Get insights from data in motion or stored/retained data, kept in AI-friendly structures for investigation.
- Power AI-native security apps: Feed consistent, high-fidelity telemetry into Databricks models and downstream security tools, enabling generative AI to act with confidence and explainability. Leverage Reef for insight-rich data to reduce compute costs and improve response times.
For SOC teams, this means less time spent triaging irrelevant alerts and more time preventing breaches. For CISOs, this means greater visibility and control across the entire enterprise, while empowering their teams to achieve more at lower costs. For the business, it means security and data ownership that scale with innovation.
A Partnership Built for the Future
Databricks’ Data Intelligence for Cybersecurity brings the scale and governance enterprises need to unify their data at rest as a central destination. With DataBahn, data arrives in Databricks already optimized – AI-powered pipelines make it usable, insightful, and actionable in real time.
This partnership goes beyond integration – it lays the foundation for a new era of cybersecurity, where data shifts from liability to advantage in unlocking generative AI for defense. Together, Databricks’ platform and DataBahn’s intelligence layer give security teams the clarity, speed, and agility they need against today’s evolving threats.
What Comes Next
The launch of Data Intelligence for Cybersecurity is only the beginning. Together, Databricks and DataBahn are helping enterprises reimagine how they collect, manage, secure, and leverage data.
The vision is clear – a platform that is:
- Lightweight and modular – collect data from any source effortlessly, including AI-powered integration for custom applications and microservices.
- Broadly integrated – DataBahn comes with a library of collectors for aggregating and transforming telemetry, while Databricks creates a unified data storage for the telemetry.
- Intelligently optimized – remove 60-80% of non-security-relevant data and keep it out of your SIEM to save on costs; eventually, make your SIEM work as a detection engine on top of Databricks as a storage layer for all security telemetry.
- Enrichment-first – apply threat intel, identify, geospatial data, and other contextual information before forwarding data into Databricks and your SIEM to make analysis and investigations faster and smarter.
- AI-ready – feeding clean, contextualized, and enriched data into Databricks to be fed into your models and your AI applications – for metrics and richer insights, they can also leverage Reef to save on compute.
This is the next era of security – and it starts with data. Together, Databricks and DataBahn provide an AI-native foundation in which telemetry is self-optimized and stored in a way to make insights instantly accessible. Data is turned into intelligence, and intelligence is turned into action.






.avif)





.avif)

.avif)







