


The Open Cybersecurity Schema Framework (OCSF) was designed to solve a fundamental problem: security data fragmentation. By offering an open and shared format, OCSF brought a shared foundational understanding of what security data should be understood, driving consistency. But every security engineer who has implemented OCSF mappings encounters the same structural challenge within weeks: the unmapped object.
This is where normalization efforts stall.
The Unmapped Object, Defined
OCSF aims to resolve fragmentation in security data by providing a shared taxonomy, including categories, event classes, and a standardized attribute dictionary, so that telemetry from disparate sources can be queried, correlated, and analyzed consistently. But this structure runs into challenges for complex and unexpected security data which does not fall neatly into the framework.
OCSF defines the unmapped object as a catch-all container for source data that doesn't map cleanly to standardized attributes. When an engineer translates a firewall log into OCSF format, fields like source IP become src_endpoint.ip, usernames normalize to actor.user.name, and timestamps align to time. These are the wins.
But source telemetry routinely contains fields that have no standard home in the schema. An MFA status indicator from an identity provider. A proprietary risk score from an EDR vendor. A vendor-specific context field that detection logic depends on. These fields don't disappear, they land in unmapped.
The unmapped object preserves data. Technically, nothing is lost. But it creates a different kind of fragmentation: structured, queryable fields alongside unstructured data that requires custom parsing for every downstream consumer. Detection engineers writing correlation rules cannot rely on unmapped content without building source-specific logic. Analysts hunting for threats must know which unmapped fields exist and how to extract them. AI systems attempting to reason across security data cannot process unmapped content without additional transformation.
The richer the source telemetry, the more content ends up unmapped. As one industry analysis observed: "Data is custom, the richer the data the more unmappable it gets. Don't be surprised if the analyst goes digging into un-normalized fields rather than common normalized fields, because that's where the piece of information they needed was buried."
This is the structural tension at the heart of OCSF adoption.
Three Causes of Mapping Gaps
Three factors drive the unmapped problem.
Schema variability at the source. Security tools emit logs in formats designed for their own ecosystems, not for interoperability. Proprietary field names, nested structures, and vendor-specific semantics mean that mapping requires deep understanding of both source format and target schema. When a vendor changes their log format, adding fields or restructuring existing ones, transformation rules break. Fields that were previously mapped may suddenly require rework. The maintenance burden compounds across hundreds of data sources.
Partial schema coverage. Some security tools don't provide enough data or context to fully populate OCSF's structured fields. Missing event class identifiers, absent process metadata, incomplete user objects, these gaps force engineers to choose between extending the schema, dropping fields, or accepting degraded normalization fidelity. None of these options are cost-free.
Field conflicts and ambiguities. Different tools use the same field name for different purposes, or represent the same concept with incompatible structures. A "status" field in one product might indicate connection state; in another, it represents authentication outcome. Resolving these conflicts requires judgment calls that must be documented, maintained, and applied consistently across all pipelines handling that source.
Organizations adopt OCSF expecting unified telemetry. What they often get is a mix of cleanly mapped fields and growing unmapped buckets that require custom handling for every query, detection rule, and investigation workflow. Organizations report spending two to four months on comprehensive OCSF implementations, and that timeline assumes stable source schemas, which rarely hold.
Three Governance Approaches
Security teams handle unmapped content in three primary ways, each with distinct trade-offs.
Strict minimum mapping. Map only the fields explicitly required by OCSF for the chosen event class. Everything else goes to unmapped. This approach preserves data completeness and avoids over-engineering the mapping layer, but it pushes complexity downstream. Detection engineers must write custom parsers for unmapped content. Analysts lose the ability to correlate on fields that could have been standardized. This approach works for organizations with simple detection requirements or limited cross-source correlation needs. It fails when unmapped fields contain the precise context needed for threat hunting or incident response.
Schema extension. OCSF supports extensions, formal mechanisms to add custom attributes to existing event classes without breaking compatibility. For fields that are critical and represent long-term requirements, creating an organization-specific extension with dedicated attributes is the most robust solution. Extension requires registration to receive a unique identifier range, preventing conflicts with the core schema or other organizations' extensions. The process enforces governance but demands ongoing maintenance: schema registries to track which extensions exist, what they contain, and which pipeline versions support them. This approach fits organizations with mature data engineering capabilities and stable telemetry requirements. It struggles when sources change frequently or when teams lack resources for extension lifecycle management.
Dynamic classification. Rather than pre-defining every mapping or manually extending schemas, this approach uses intelligent systems to classify and route data in real time. The pipeline learns source schemas, identifies semantic equivalents, and maps fields dynamically, elevating what would be unmapped into structured, queryable attributes without manual rule creation.
This is where the architectural gap exists in most OCSF implementations. Static mapping rules cannot adapt to schema drift. Manual extension processes cannot scale to hundreds of sources. Unmapped buckets grow into ungovernable data graveyards.
Normalization as a Pipeline Problem
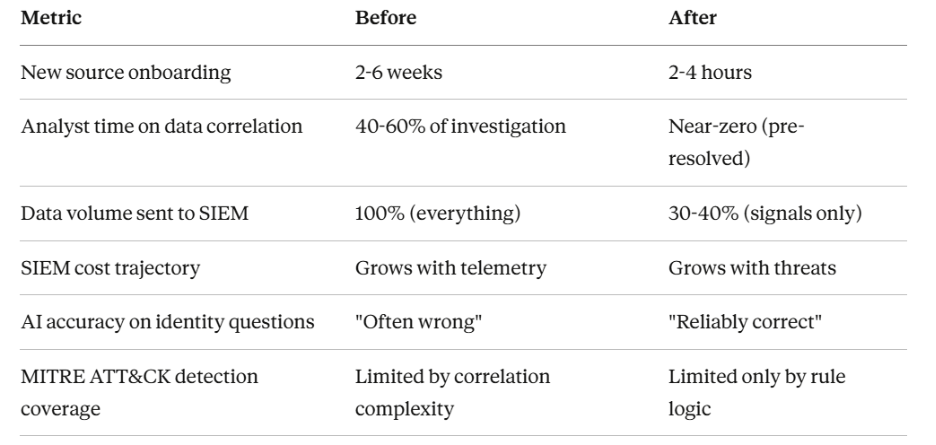
The unmapped field problem is fundamentally a pipeline architecture problem. Normalization happens in transit, not at rest. Decisions about what maps where, what extends the schema, and what falls into catch-all containers must be made in flight, at the speed of telemetry ingestion.
Traditional approaches treat parsing, normalization, and transformation as static configurations. Engineers write mapping rules, deploy them, and hope sources don't change. When they do, and sources always change, brittle pipelines break. Fields that should be normalized end up unmapped. Detection coverage degrades silently. No one notices until an investigation fails or a compliance audit surfaces gaps.
This is where Databahn comes in. The platform approaches OCSF normalization as a continuous, AI-assisted process rather than a one-time configuration exercise.
Cruz, Databahn's agentic AI, builds an understanding of source schemas as they evolve. It automatically detects schema drift and adapts transformations without manual intervention. When a vendor adds a new field or restructures an existing one, the pipeline doesn't break, it learns. Fields that would traditionally fall into unmapped buckets are intelligently classified and routed to appropriate schema locations, or flagged for extension when no suitable mapping exists.
The platform maintains schema consistency across heterogeneous data models in-line, rather than post-ingestion. This means SIEM correlation rules and detection logic operate on unified, structured data, not a mix of normalized fields and unmapped JSON blobs that require custom handling. Analysts spend time on investigations, not digging through catch-all containers for buried context.
For enterprises already navigating OCSF adoption with Amazon Security Lake, Microsoft Sentinel, or Splunk, Databahn provides the transformation layer that turns partial mappings into comprehensive normalization.
Governance Practices That Reduce Drift
Regardless of the approach chosen, governance practices reduce unmapped field accumulation over time.
Document every mapping decision. When a field goes to unmapped, record why. When an extension is created, define its scope and intended consumers. Detection engineers, data engineers, and analysts need to understand how data flows through the schema. Ambiguity compounds across teams and time.
Establish feedback loops with downstream consumers. The teams writing detection rules, hunting for threats, and investigating incidents are the first to know when unmapped fields contain critical context. Their pain points should drive mapping priorities and extension decisions.
Monitor unmapped field growth. If the unmapped object is expanding faster than structured fields, something is wrong architecturally. Either sources are changing faster than mappings can adapt, or the mapping strategy is too conservative for the organization's detection requirements.
Pin analytics and detection content to specific OCSF versions. Schema evolution is inevitable. Content repositories that reference explicit versions prevent breaking changes from silently degrading detection coverage when the schema updates.
The Architectural Choice
OCSF adoption is not a checkbox exercise. It is an architectural decision with downstream implications for every detection rule, investigation workflow, and AI application built on security data.
The unmapped field problem reveals a fundamental tension: static schemas cannot keep pace with dynamic telemetry. Organizations face a choice. Continue retrofitting manual mappings onto evolving sources, accepting growing unmapped buckets as inevitable. Or invest in infrastructure that treats normalization as a continuous, intelligent process, governance that happens in flight, not after storage.
The future of security data normalization is not more catch-all containers. It is pipelines that understand schemas, adapt to drift, and ensure that critical context reaches analysts and AI systems in structured, queryable form.

.png)

.png)








.avif)

.avif)







