.avif)


Enterprise leaders are racing to capture the promise of Generative AI. The vision is compelling: security teams that respond in seconds, IT operations that optimize themselves, executives who can query enterprise performance in natural language. Yet for all the hype, reality is sobering.
MIT research shows that 95% of enterprise AI projects fail. The 5% that succeed share one trait: they don’t bolt GenAI onto legacy systems; they build on infrastructure that was designed for AI from the ground up. OpenAI recently launched its Forward Deployed Engineer (FDE) program for precisely this reason while acknowledging that enterprise AI adoption has become bottlenecked not by imagination, but by architecture.
For CISOs, CIOs, CTOs, and CEOs, this is no longer just about experimentation. It’s about whether your enterprise AI adoption strategy will scale securely, reduce operational risk, and deliver competitive advantage.
What is AI-native infrastructure?
“AI-native” is more than a buzzword. It represents a decisive break from retrofitting existing tools and processes to accommodate the generative AI enterprise transformation.
AI-native infrastructure is built to anticipate the needs of machine intelligence, not adapt to them later. Key characteristics include:
- AI-ready structured data stores → optimized for training, reasoning, and multi-modal input.
- AI-first protocols like Model Context Protocol (MCP) → enabling AI agents to safely and seamlessly connect with enterprise systems.
- Semantic layers and context-rich data fabrics → ensuring that data is enriched, normalized, and explainable for both humans and machines.
- Agentic AI operations → autonomous systems that can parse, repair, and optimize data pipelines in real time.
- Headless architectures → decoupling data from applications to prevent tool lock-in and accelerate interoperability.
Contrast this with legacy stacks: rigid schemas, siloed tools, proprietary formats, and brittle integrations. These were designed for dashboards and humans – not reasoning engines and autonomous agents. AI-native infrastructure, by design, makes AI a first-class citizen of the enterprise technology stack.
The impact of GenAI failure in enterprises
The promise of the GenAI enterprise transformation is breathtaking: instant responsiveness, autonomous insight, and transformative workflows. But in too many enterprises, the reality is wasted effort, hallucinated outputs, operational risks, and even new security threats.
Wasted Time & Effort, with Little ROI
Despite billions of dollars in investment, generative AI has failed to deliver meaningful business outcomes for most organizations. The MIT study cited poor integration, unrealistic expectations, and a lack of industry-specific adaptation as the reason for 95% of enterprise AI projects are failing. You end up with pilots, not platforms - costs spiral, momentum stalls, and leaders grow skeptical.
Hallucinations, Errors, & Reputational Damage
GenAI systems often generate outputs that are plausible but wrong. Deloitte warns that hallucinations can lead to faulty decisions, regulatory penalties, and public embarrassment. Inaccuracy isn’t just an annoyance – it’s a business liability.
Security & Compliance Risks
Generative AI increases cyber vulnerability in unexpected ways:
- Deepfakes and phishing → impersonating leaders to trick employees.
- Malicious prompt manipulation → steering AI to disclose sensitive data.
- System vulnerabilities → adversarial prompts that can inject malicious code into enterprise workflows.
- Shadow AI & Governance Blind Spots
When organizations rush into generative AI without governance, “shadow AI” proliferates – teams adopt AI tools without oversight, risking data exposure and non-compliance. PwC underscores that GenAI amplifies threats related to privacy, compliance, intellectual property, and legal risk, reinforcing the need for trust-by-design, not just speed.
AI Arms Race – Defenders Can’t Keep Up
Cybercriminals are adopting GenAI just as quickly, if not faster. Security leaders report they can’t match the pace of AI-powered adversaries. The risk isn’t just hallucination – it’s being outpaced in an escalating AI arms race.
Without a foundation built for AI – one that guards against hallucination, ensures governance, secures against manipulation, and embeds human-in-the-loop oversight –Generative AI becomes not a driver of transformation, but a vector of failure.
Why are SOCs struggling to harness the potential for Generative AI
A few systemic traps in cybersecurity and telemetry ecosystems:
- The Legacy Retrofit Problem
Duct-taping GenAI onto SIEMs, CRMs, or observability platforms built for human dashboards doesn’t work. These systems weren’t built for autonomous reasoning, and they choke on unstructured, noisy, or redundant data.
- Data Chaos and Schema Drift
AI can’t learn from broken pipelines. Unpredictable data flows, ungoverned enrichment, and constant schema drift undermine trust. The result: hallucinations, blind spots, and brittle AI outputs.
- The DIY Trap
Some enterprises try to build AI-ready infra in-house. Research shows this approach rarely scales: the talent is scarce, the maintenance overhead crippling, and the results fragile. Specialized vendors succeed where DIY fails.
- Cost Explosion
When data isn’t filtered, tiered, and governed before it reaches AI models, compute and storage bills spiral. Enterprises pay to move and process irrelevant data, burning millions without value.
AI can’t thrive on yesterday’s plumbing. Without AI-native foundations, every GenAI investment risks becoming another line item in the 95% failure statistic.
Principles and Best Practices for AI-native infrastructure
So what does it take to build for the 5% that succeed? Forward-looking enterprises are coalescing around four principles:
- AI-Ready Data
Structured, normalized, enriched, and explainable. AI outputs are only as good as the inputs; noisy or incomplete data guarantees failure.
- Interoperability and Open Protocols
Embrace standards like MCP, APIs, and headless designs to prevent lock-in and empower agents to operate across the stack.
- Autonomous Operations
Agentic AI systems can parse new data sources, repair schema drift, track telemetry health, and quarantine sensitive information – automatically.
- Future-Proof Scalability
Design for multi-modal AI: text, logs, video, OT telemetry. Tomorrow’s AI won’t just parse emails; it will correlate camera feeds with log data and IoT metrics to detect threats and inefficiencies.
External research reinforces this: AI models perform disproportionately better when trained on high-quality, AI-ready data. In fact, data readiness is a stronger predictor of success than model selection itself.
The lesson: enterprises must treat AI-native infrastructure as the strategic layer beneath every GenAI investment.
Why we built DataBahn this way
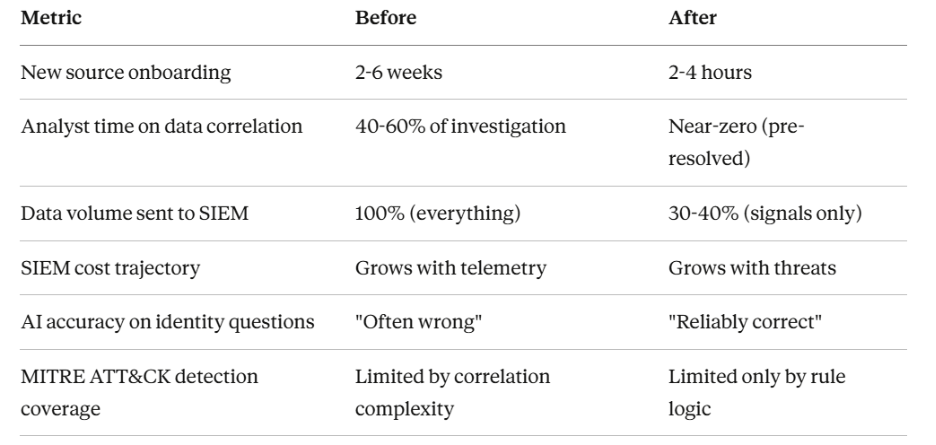
At DataBahn, we saw this shift coming. That’s why our platform was not adapted from observability tools or legacy log shippers – it was built AI-native from day one.
We believe the AI-powered SOC of the future will depend on infrastructure that can collect, enrich, orchestrate, and optimize telemetry for AI, not just for humans. We designed our products to be the beating heart of that transformation: a foundation where agentic AI can thrive, where enterprises can move from reactive dashboards to proactive, AI-driven operations.
This isn’t about selling tools. It’s about ensuring enterprises don’t fall into the 95% that fail.
The question every CXO must answer
Generative AI isn’t waiting. Your competitors are already experimenting, learning, and building AI-native foundations. The real question is no longer if GenAI will transform your enterprise, but whether your infrastructure will allow you to keep pace.
Legacy plumbing won’t carry you into the AI era. AI-native infrastructure isn’t a luxury; it’s table stakes for survival in the coming decade.
For CXOs, the call to action is clear: audit your foundations, re-architect for AI, and choose partners who can help you move fast without compromise.
At DataBahn, we’re looking forward to powering this future.

.png)

.png)








.avif)

.avif)







