.avif)


Enterprises are rapidly shifting to hybrid data pipeline security as the cornerstone of modern cybersecurity strategy. Telemetry data no longer lives in a single environment—it flows across multi-cloud services, on-premise infrastructure, SaaS platforms, and globally distributed OT/IoT systems. For CISOs, CIOs, and CTOs, the challenge is clear: how do you secure hybrid data pipelines, cut SIEM costs, and prepare telemetry for AI-driven security operations?
With global data creation expected to hit 394 zettabytes by 2028, the stakes are higher than ever. Legacy collectors and agent-based pipelines simply can’t keep pace, often driving up costs while creating blind spots. To meet this challenge, organizations need systems designed to encrypt, govern, normalize, and make telemetry AI-ready across every environment. This guide covers the best practices security leaders should adopt in 2025 and 2026 to protect critical data, reduce vulnerabilities, and future-proof their SOC.
What enterprises need today is a hybrid data pipeline security strategy – one that ensures telemetry is securely collected, governed, and made AI-ready across all environments. This article outlines the best practices for securing hybrid data pipelines in 2025 and 2026: from reducing blind spots to automating governance, to preparing pipelines for the AI-native SOC.
What is a Hybrid Data Pipeline?
In the context of telemetry, hybrid data pipelines refer to multi-environment data networks. This can consist of a collection of the following –
- Cloud: Single cloud (one provider, such as AWS, Azure, GCP, etc.) or multiple cloud providers and containers for logs and SaaS telemetry;
- On-Prem: Firewalls, databases, legacy infrastructure;
- OT/IoT: Plants, manufacturing sensors, medical devices, fleet, and logistics tracking
One of our current customers serves as a great example. They are one of the largest biopharmaceutical companies in the world, with multiple business units and manufacturing facilities globally. They operate a multi-cloud environment, have on-premises systems, and utilize geospatially distributed OT/IoT sensors to monitor manufacturing, logistics, and deliveries. Their data pipelines are hybrid as they are collecting data from cloud, on-prem, and OT/IoT sources.
How can Hybrid Data Pipelines be secured?
Before adopting DataBahn, the company relied on SIEM collectors for telemetry data but struggled to manage data flow over a disaggregated network. They operated 6 data centers and four additional on-premises locations, producing over four terabytes of data daily. Their security team struggled to –
- Track and manage multiple devices and endpoints, which number in the tens of thousands;
- Detect, mask, and quarantine sensitive data that was occasionally being sent across their systems;
- Build collection rules and filters to optimize and reduce the log volume being ingested into their SIEM
Hybrid Data Pipeline Security is the practice of ensuring end-to-end security, governance, and resilience across disparate hybrid data flows. It means:
- Encrypting telemetry in motion and at rest.
- Masking sensitive fields (PII, PHI, PCI data) before they hit downstream tools.
- Normalizing into open schemas (e.g., OCSF, CIM) to reduce vendor lock-in.
- Detecting pipeline drift, outages, and silent data loss proactively.
In other words, hybrid data pipeline security is about building a sustainable security data and telemetry management approach that protects your systems, reduces vulnerabilities, and enables you to trust your data while tracking and governing your system easily.
Common Security Challenges with Hybrid Data Pipelines
Every enterprise security team grappling with hybrid data pipelines knows that complexity kills clarity and leaves gaps that make them more vulnerable to threat actors or missing essential signals.
- Unprecedented Complexity from Data Variety:
Hybrid systems span cloud, on-prem, OT, and SaaS environments. That means juggling structured, semi-structured, and unstructured data from myriad sources, all with unique formats and access controls. Security professionals often struggle to unify this data into a continuously monitored posture. - Overwhelmed SIEMs & Alert Fatigue:
Traditional SIEMs weren’t built for such scale or variety. Hybrid environments inflate alert volumes, triggering fatigue and weakening detection responses. Analysts often ignore alerts – some of which could be critical. - Siloed Threat Investigation:
Data scattered across domains adds friction to incident triage. Analysts must navigate different formats, silos, and destinations to piece together threat narratives. This slows investigations and increases risk. - Security Takes a Backseat to Data Plumbing and Operational Overhead:
As teams manage integration, agent sprawl, telemetry health, and failing pipelines, strategic security takes a backseat. Engineers spend their time patching collectors instead of reducing vulnerabilities or proactively defending the enterprise.
Why this matters in 2025 and 2026
These challenges aren’t just operational problems; they threaten strategic security outcomes. With Cloud Repatriation becoming a trend among enterprises, with 80% of IT decision-makers moving some flows away from cloud systems [IDC Survey, 2024], companies need to ensure their hybrid systems are equipped to deal with the security challenges of the future.
- Cloud Cost Pressures Meet Telemetry Volume:
Cloud expenses rise, telemetry grows, and sensitive data (like PII) floods systems. Securing and masking data at scale is a daunting task. - Greater Regulatory Scrutiny:
Regulations such as GDPR, HIPAA, and NIS2 now hold telemetry governance to the same scrutiny as system-level defenses. Pipeline breaches equal pipeline failures in risk. - AI Demands Clean, Contextual Data:
AI-driven SecOps depends on high-quality, curated telemetry. Messy or ungoverned data undermines model accuracy and trustworthiness. - Visibility as Strategic Advantage:
Compromising on visibility becomes the norm for many organizations, leading to blind spots, delayed detection, and fractured incident response. - Acceptance of Compromise:
Recent reports reveal that over 90% of security leaders accept trade-offs in visibility or integration, which is an alarming normalization of risk due to strained resources and fatigued security teams.
In 2025, hybrid pipeline security is about building resilience, enforcing compliance, and preparing for AI – not just reducing costs.
Best Practices for Hybrid Data Pipeline Security
- Filter and Enrich at the Edge:
Deploy collectors to reduce noise (such as heartbeats) before ingestion and enhance telemetry with contextual metadata (asset, geo, user) to improve alert quality. - Normalize into Open Schemas:
Use OCSF or CIM to standardize telemetry while boosting portability and avoiding vendor lock-in, while enhancing AI and cross-platform analytics. - Automate Governance & Data Masking:
Implement policy-driven redaction and build systems that automatically remove PII/PHI to lower compliance risks and prevent leaks. - Multi-Destination Routing:
Direct high-value data to SIEM, send bulk logs to cold storage, and route enriched datasets to cold storage or data lakes, reducing costs and maximizing utility. - Schema Drift Detection:
Utilize AI to identify and adapt to log format changes dynamically to maintain pipeline resilience despite upstream alterations. - Agent / Agentless Optimization:
Unify tooling into a single collector with hybrid (agent + agentless) capabilities to cut down sprawl and optimize data collection overhead. - Strategic Mapping to MITRE ATT&CK:
Link telemetry to MITRE ATT&CK tactics and techniques – improving visibility of high-risk behaviors and focusing collection efforts for better detection. - Build AI-Ready Pipelines: Ensure telemetry is structured, enriched, and ready for queries, enabling LLMs and agentic AI to provide accurate, actionable insights quickly.
How DataBahn can help
The company we used as an example earlier came to DataBahn looking for SIEM cost reduction, and they achieved a 50% reduction in cost during the POC with minimal use of DataBahn’s in-built volume reduction rules. However, the bigger reason they are a customer today is because they saw the data governance and security value in using DataBahn to manage their hybrid data pipelines.
For the POC, the company routed logs from an industry-leading XDR solution to DataBahn. In just the first week, DataBahn discovered and tracked over 40,000 devices and helped identify more than 3,000 silent devices; the platform also detected and proactively masked over 50,000 instances of passwords logged in clear text. These unexpected benefits of the platform further enhanced the ROI the company saw in the volume reduction and SIEM license fee savings.
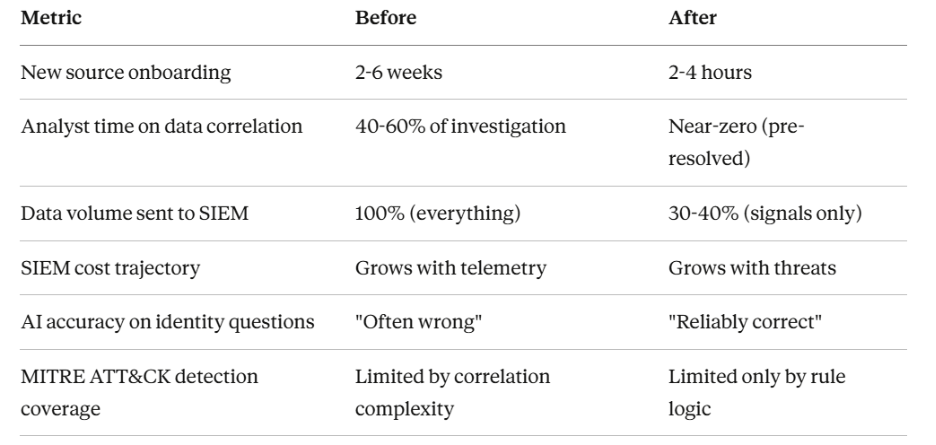
Enterprises that adopt DataBahn’s hybrid data pipeline approach realize measurable improvements in security posture, operational efficiency, and cost control.
- Reduced SIEM Costs Without Losing Visibility
By intelligently filtering telemetry at the source and routing only high-value logs into the SIEM, enterprises regularly cut ingestion volumes by 50% or more. This reduces licensing costs while preserving complete detection coverage. - Unified Visibility Across IT and OT
Security leaders finally gain a single control plane across cloud, on-prem, and operational environments. This eliminates silos and enables analysts to investigate incidents with context from every corner of the enterprise. - Stronger, More Strategic Detection
Using agentic AI, DataBahn automatically maps available logs against frameworks like MITRE ATT&CK, identifies visibility gaps, and guides teams on what to onboard next. This ensures the detection strategy aligns directly with the threats most relevant to the business. - Faster Incident Response and Lower MTTR
With federated search and enriched context available instantly, analysts no longer waste hours writing queries or piecing together data from multiple sources. Response times shrink dramatically, reducing exposure windows and improving resilience. - Future-Proofed for AI and Compliance
Enriched, normalized telemetry means enterprises are ready to deploy AI for SecOps with confidence. At the same time, automated data masking and governance ensure sensitive data is protected and compliance risks are minimized.
In short: DataBahn turns telemetry from a cost and complexity burden into a strategic enabler – helping enterprises defend faster, comply smarter, and spend less.
Conclusion
Building and securing hybrid data pipelines isn’t just an option for enterprise security teams; it is a strategic necessity and a business imperative, especially as risk, compliance, and security posture become vital aspects of enterprise data policies. Best practices now include early filtration, schema normalization, PII masking, aligning with security frameworks (like MITRE ATT&CK), and AI-readiness. These capabilities not only provide cost savings but also enable enterprise security teams to operate more intelligently and strategically within their hybrid data networks.
Suppose your enterprise is using or is planning to use a hybrid data system and wants to build a sustainable and secure data lifecycle. In that case, they need to see if DataBahn’s AI-driven, security-native hybrid data platform can help them transform their telemetry from a cost center into a strategic asset.
Ready to benchmark your telemetry collection against the industry’s best hybrid security data pipeline? Book a DataBahn demo today!

.png)

.png)








.avif)

.avif)







