In their article about how banks can extract value from a new generation of AI technology, notable strategy and management consulting firm McKinsey identified AI-enabled data pipelines as an essential part of the ‘Core Technology and Data Layer’. They found this infrastructure to be necessary for AI transformation, as an important intermediary step in the evolution banks and financial institutions will have to make for them to see tangible results from their investments in AI.
The technology stack for the AI-powered banking of the future relies greatly on an increased focus on managing enterprise data better. McKinsey’s Financial Services Practice forecasts that with these tools, banks will have the capacity to harness AI and “… become more intelligent, efficient, and better able to achieve stronger financial performance.”
What McKinsey says
The promise of AI in banking
The authors point to increased adoption of AI across industries and organizations, but the depth of the adoption remains low and experimental. They express their vision of an AI-first bank, which -
Reimagines the customer experience through personalization and streamlined, frictionless use across devices, for bank-owned platforms and partner ecosystems
Leverages AI for decision-making, by building the architecture to generate real-time insights and translating them into output which addresses precise customer needs. (They could be talking about Reef)
Modernizes core technology with automation and streamlined architecture to enable continuous, secure data exchange (and now, Cruz)
They recommend that banks and financial service enterprises set a bold vision for AI-powered transformation, and root the transformation in business value.
AI stack powered by multiagent systems
The true potential of AI will require banks of the future to tread beyond just AI models, the authors claim. With embedding AI into four capability layers as the goal, they identify ‘data and core tech’ as one of those four critical components. They have augmented an earlier AI capability stack, specifically adding data preprocessing, vector databases, and data post-processing to create an ‘enterprise data’ part of the ‘core technology and data layer’. They indicate that this layer would build a data-driven foundation for multiple AI agents to deliver customer engagement and enable AI-powered decision-making across various facets of a bank’s functioning.
Our perspective
Data quality is the single greatest predictor of LLM effectiveness today, and our current generation of AI tools are fundamentally wired to convert large volumes of data into patterns, insights, and intelligence. We believe the true value of enterprise AI lies in depth, where Agentic AI modules can speak and interact with each other while automating repetitive tasks and completing specific and niche workstreams and workflows. This is only possible when the AI modules have access to purposeful, meaningful, and contextual data to rely on.
We are already working with multiple banks and financial services institutions to enable data processing (pre and post), and our Cruz and Reef products are deployed in many financial institutions to become the backbone of their transformation into AI-first organizations.
Are you curious to see how you can come closer to building the data infrastructure of the future? Set up a call with our experts to see what’s possible when data is managed with intelligence.
Abishek Ganesan
Marketing Manager
At DataBahn.ai, Abishek leads the content marketing charter and helps technology, security, and data leaders worldwide understand how to unlock value from data through DataBahn's pioneering data fabric solution, which transforms enterprise data management. His diverse experience–spanning freelancing, agency work, an early-stage startup, and running a small business–sets me apart. This breadth has honed my ability to develop marketing strategies that balance immediate growth and long-term brand equity.
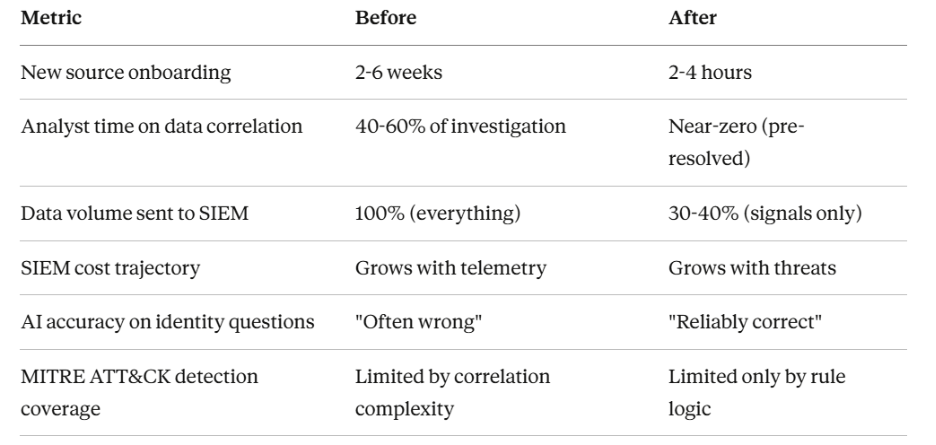
When identity breaches cost an average of $4.8 million and 84% of organizations report direct business impact from credential attacks, you'd expect AI-powered security tools to be the answer.
Instead, security leaders are discovering that their shiny new AI copilots:
Miss obvious attack chains because user IDs don't match across systems
Generate confident-sounding analysis based on incomplete information
Can't answer simple questions like "show me everything this user touched in the last 24 hours"
The problem isn't artificial intelligence. It's artificial data quality.
Watch an Attack Disappear in Your Data
Here's a scenario that plays out daily in enterprise SOCs:
Attacker compromises credentials via phishing
Logs into cloud console → CloudTrail records arn:aws:iam::123456:user/jsmith
Exfiltrates via collaboration tool → Slack logs U04ABCD1234
Five steps. One attacker. One victim.
Your SIEM sees five unrelated events. Your AI sees five unrelated events. Your analysts see five separate tickets. The attacker sees one smooth path to your data.
This is the identity stitching problem—and it's why your AI can't trace attack paths that a human adversary navigates effortlessly.
Why Your Security Data Is Working Against You
Modern enterprises run on 30+ security tools. Here's the brutal math:
Enterprise SIEMs process an average of 24,000 unique log sources
Those same SIEMs have detection coverage for just 21% of MITRE ATT&CK techniques
Organizations ingest less than 15% of available security telemetry due to cost
More data. Less coverage. Higher costs.
This isn't a vendor problem. It's an architecture problem—and throwing more budget at it makes it worse.
Why Traditional Approaches Keep Failing
Approach 1: "We'll normalize it in the SIEM"
Reality: You're paying detection-tier pricing to do data engineering work. Custom parsers break when vendors change formats. Schema drift creates silent failures. Your analysts become parser maintenance engineers instead of threat hunters.
Approach 2: "We'll enrich at query time"
Reality: Queries become complex, slow, and expensive. Real-time detection suffers because correlation happens after the fact. Historical investigations become archaeology projects where analysts spend 60% of their time just finding relevant data.
Approach 3: "We'll train the AI on our data patterns"
Reality: You're training the AI to work around your data problems instead of fixing them. Every new data source requires retraining. The AI learns your inconsistencies and confidently reproduces them. Garbage in, articulate garbage out.
None of these approaches solve the root cause: your data is fragmented before it ever reaches your analytics.
The Foundation That Makes Everything Else Work
The organizations seeing real results from AI security investments share one thing: they fixed the data layer first.
Not by adding more tools. By adding a unification layer between their sources and their analytics—a security data pipeline that:
1. Collects everything once Cloud logs, identity events, SaaS activity, endpoint telemetry—without custom integration work for each source. Pull-based for APIs, push-based for streaming, snapshot-based for inventories. Built-in resilience handles the reliability nightmares so your team doesn't.
2. Translates to a common language So jsmith in Active Directory, jsmith@company.com in Azure, John Smith in Salesforce, and U04ABCD1234 in Slack all resolve to the same verified identity—automatically, at ingestion, not at query time.
3. Routes by value, not by volume High-fidelity security signals go to real-time detection. Compliance logs go to cost-effective storage. Noise gets filtered before it costs you money. Your SIEM becomes a detection engine, not an expensive data warehouse.
4. Preserves context for investigation The relationships between who, what, when, and where that investigations actually need—maintained from source to analyst to AI.
What This Looks Like in Practice
The 70% reduction in SIEM-bound data isn't about losing visibility—it's about not paying detection-tier pricing for compliance-tier logs.
More importantly: when your AI says "this user accessed these resources from this location," you can trust it—because every data point resolves to the same verified identity.
The Strategic Question for Security Leaders
Every organization will eventually build AI into their security operations. The question is whether that AI will be working with unified, trustworthy data—or fighting the same fragmentation that's already limiting your human analysts.
The SOC of the future isn't defined by which AI you choose. It's defined by whether your data architecture can support any AI you choose.
Questions to Ask Before Your Next Security Investment
Before you sign another security contract, ask these questions:
For your current stack:
"Can we trace a single identity across cloud, SaaS, and endpoint in under 60 seconds?"
"How long does it take to onboard a new log source end-to-end?"
For prospective vendors:
"Do you normalize to open standards like OCSF, or proprietary schemas?"
"How do you handle entity resolution across identity providers?"
"What routing flexibility do we have for cost optimization?"
"Does this add to our data fragmentation, or help resolve it?"
If your team hesitates on the first set, or vendors look confused by the second—you've found your actual problem.
The foundation comes first. Everything else follows.
Stay tuned to the next article on recommendations for architecture of the AI-enabled SOC
What's your experience? Are your AI security tools delivering on their promise, or hitting data quality walls? I'd love to hear what's working (or not) in the comments.
The managed security services market isn’t struggling with demand. Quite the opposite. As attack surfaces sprawl across cloud, SaaS, endpoints, identities, and operational systems, businesses are leaning more heavily than ever on MSSPs to deliver security outcomes they can’t realistically build in-house.
But that demand brings a different kind of pressure – customers aren’t buying coverage anymore. They’re looking to pay for confidence and reassurance: full visibility, consistent control, and the operational maturity to handle complexity, detect attacks, and find gaps to avoid unpleasant surprises. For MSSP leaders, trust has become the real product.
That trust isn’t easy to deliver. MSSPs today are running on deeply manual, repetitive workflows: onboarding new customers source by source, building pipelines and normalizing telemetry tool by tool, and expending precious engineering bandwidth on moving and managing security data that doesn’t meaningfully differentiate the service. Too much of their expertise is consumed in mechanics that are critical, but not meaningful.
The result is a barrier to scale. Not because MSSPs lack customers or talent, but because their operating model forces highly skilled teams to solve the same data problems over and over again. And that constraint shows up early. The first impression of an MSSP for a customer is overshadowed by the onboarding experience, when their services and professionalism are tested in tangible ways beyond pitches and promises. The speed and confidence with which an MSSP can move to complete, production-grade security visibility becomes the most lasting measure of their quality and effectiveness.
Industry analysis from firms such as D3 Security points to an inevitable consolidation in the MSSP market. Not every provider will scale successfully. The MSSPs that do will be those that expand efficiently, turning operational discipline into a competitive advantage. Efficiency is no longer a back-office metric; it’s a market differentiator.
That reality shows up early in the customer lifecycle most visibly, during onboarding. Long before detection accuracy or response workflows are evaluated, a more basic question is answered. How quickly can an MSSP move from a signed contract to reliable, production-grade security telemetry? Increasingly, the answer determines customer confidence, margin structure, and long-term competitiveness.
The Structural Mismatch: Multi-Customer Services and Manual Onboarding
MSSPs operate as professional services organizations, delivering security operations across many customer environments simultaneously. Each environment must remain strictly isolated, with clear boundaries around data access, routing, and policy enforcement. At the same time, MSSP teams require centralized visibility and control to operate efficiently.
In practice, many MSSPs still onboard each new customer as a largely independent effort. Much of the same data engineering and configuration work is repeated across customers, with small but critical variations. Common tasks include:
Manual configuration of data sources and collectors
Custom parsing and normalization of customer telemetry
Customer-specific routing and policy setup
Iterative tuning and validation before data is considered usable
This creates a structural mismatch. The same sources appear again and again, but the way those sources must be governed, enriched, and analyzed differs for each customer. As customer counts grow, repeated investment of engineering time becomes a significant efficiency bottleneck.
Senior engineers are often pulled into onboarding work that combines familiar pipeline mechanics with customer-specific policies and downstream requirements. Over time, this leads to longer deployment cycles, greater reliance on scarce expertise, and increasing operational drag.
This is not a failure of tools or talent. Skilled engineers and capable platforms can solve individual onboarding problems. The issue lies in the onboarding model itself. When knowledge exists primarily in ad-hoc engineering work, scripts, and tribal knowledge, it cannot be reused effectively at scale.
Why Onboarding Has Become a Bottleneck
At small scales, the inefficiency is tolerable. As MSSPs aim to scale, it becomes a growth constraint.
As MSSPs grow, onboarding must balance two competing demands:
Consistency, to ensure operational reliability across multiple customers; and
Customization, to respect each customer’s unique telemetry, data governance, and security posture.
Treating every environment identically introduces risk and compliance gaps. But customizing every pipeline manually introduces inefficiency and drag. This trade-off is what now defines the onboarding challenge for MSSPs.
Consider two customers using similar toolsets. One may require granular visibility into transactional data for fraud detection; the other may prioritize OT telemetry to monitor industrial systems. The mechanics of ingesting and moving data are similar, yet the way that data is treated — its routing, enrichment, retention, and analysis — differs significantly. Traditional onboarding models rebuild these pipelines repeatedly from scratch, multiplying engineering effort without creating reusable value.
The bottleneck is not the customization itself but the manual delivery of that customization. Scaling onboarding efficiently requires separating what must remain bespoke from what can be standardized and reused.
From Custom Setup to Systemized Onboarding
Incremental optimizations help only at the margins. Adding engineers, improving runbooks, or standardizing steps does not change the underlying dynamic. The same contextual work is still repeated for each customer.
The reason is that onboarding combines two fundamentally different kinds of work.
First, there is data movement. This includes setting up agents or collectors, establishing secure connections, and ensuring telemetry flows reliably. Across customers, much of this work is familiar and repeatable.
Second, there is data treatment. This includes policies, routing, enrichment, and detection logic. This is where differentiation and customer value are created.
When these two layers are handled together, MSSPs repeatedly rebuild similar pipelines for each customer. When handled separately, the model becomes scalable. The “data movement” layer becomes a standardized, automated process, while “customization” becomes a policy layer that can be defined, validated, and applied through governed configuration.
This approach allows MSSPs to maintain isolation and compliance while drastically reducing repetitive engineering work. It shifts human expertise upstream—toward defining intent and validating outcomes rather than executing low-level setup tasks.
In other words, systemized onboarding transforms onboarding from an engineering exercise into an operational discipline.
Applying AI to Onboarding Without Losing Control
Once onboarding is reframed in this way, AI can be applied effectively and responsibly.
AI-driven configuration observes incoming telemetry, identifies source characteristics, and recognizes familiar ingestion patterns. Based on this analysis, it generates configuration templates that define how pipelines should be set up for a given source type. These templates cover deployment, parsing, normalization, and baseline governance.
Importantly, this approach does not eliminate human oversight. Engineers review and approve configuration intent before it is executed. Automation handles execution consistently, while human expertise focuses on defining and validating how data should be treated.
Platforms such as Databahn support a modular pipeline model. Telemetry is ingested, parsed, and normalized once. Downstream treatment varies by destination and use case. The same data stream can be routed to a SIEM with security-focused enrichment and to analytics platforms with different schemas or retention policies, without standing up entirely new pipelines.
This modularity preserves customer-specific outcomes while reducing repetitive engineering work.
Reducing Onboarding Time by 90%
When onboarding is systemized and supported by AI-driven configuration, the reduction in time is structural rather than incremental.
AI-generated templates eliminate the need to start from a blank configuration for each customer. Parsing logic, routing rules, enrichment paths, and isolation policies no longer need to be recreated repeatedly. MSSPs begin onboarding with a validated baseline that reflects how similar data sources have already been deployed.
Automated configuration compresses execution time further. Once intent is approved, pipelines can be deployed through controlled actions rather than step-by-step manual processes. Validation and monitoring are integrated into the workflow, reducing handoffs and troubleshooting cycles.
In practice, this approach has resulted in onboarding time reductions of up to 90 percent for common data sources. What once required weeks of coordinated effort can be reduced to minutes or hours, without sacrificing oversight, security, or compliance.
What This Unlocks for MSSPs
Faster onboarding is only one outcome. The broader advantage lies in how AI-driven configuration reshapes MSSP operations:
Reduced time-to-value: Security telemetry flows earlier, strengthening customer confidence and accelerating value realization.
Parallel onboarding: Multiple customers can be onboarded simultaneously without overextending engineering teams.
Knowledge capture and reuse: Institutional expertise becomes encoded in templates rather than isolated in individuals.
Predictable margins: Consistent onboarding effort allows costs to scale more efficiently with revenue.
Simplified expansion: Adding new telemetry types or destinations no longer creates operational variability.
Collectively, these benefits transform onboarding from an operational bottleneck into a competitive differentiator. MSSPs can scale with control, predictability, and confidence — qualities that increasingly define success in a consolidating market.
Onboarding as the Foundation for MSSP Scale
As the MSSP market matures, efficient scale has become as critical as detection quality or response capability. Expanding telemetry, diverse customer environments, and cost pressure require providers to rethink how their operations are structured.
In Databahn’s model, multi-customer support is achieved through a beacon architecture. Each customer operates in an isolated data plane, governed through centralized visibility and control. This model enables scale only when onboarding is predictable and consistent.
Manual, bespoke onboarding introduces friction and drift. Systemized, AI-driven onboarding turns the same multi-customer model into an advantage. New customers can be brought online quickly, policies can be enforced consistently, and isolation can be preserved without slowing operations.
By encoding operational knowledge into templates, applying it through governed automation, and maintaining centralized oversight, MSSPs can scale securely without sacrificing customization. The shift is not merely about speed — it’s about transforming onboarding into a strategic enabler of growth.
Conclusion
The MSSP market is evolving toward consolidation and maturity, where efficiency defines competitiveness as much as capability. The challenge is clear: onboarding new customers must become faster, more consistent, and less dependent on manual engineering effort.
AI-driven configuration provides the structural change required to meet that challenge. By separating repeatable data movement from customer-specific customization, and by automating the configuration of the former through intelligent templates, MSSPs can achieve both speed and precision at scale.
In this model, onboarding is no longer a friction point; it becomes the operational foundation that supports growth, consistency, and resilience in an increasingly demanding security landscape.
For most CIOs and SRE leaders, observability has grown into one of the most strategic layers of the technology stack. Cloud-native architectures depend on it, distributed systems demand it, and modern performance engineering is impossible without it. And yet, even as enterprises invest heavily in their platforms, pipelines, dashboards, and agents, the experience of achieving true observability feels harder than it should be.
Telemetry and observability systems have become harder to track and manage than ever before. Data flows, sources, and volumes shift and scale unpredictably. Different cloud containers and applications straddle different regions and systems, introducing new layers of complexity and chaos that enterprises never built these systems for.
In this environment, the traditional assumptions underpinning observability begin to break down. The tools are more capable than ever, but the architecture that feeds them has not kept pace. The result is a widening gap between what organizations expect observability to deliver and what their systems are actually capable of supporting.
Observability is no longer a tooling problem. It is a challenge to create future-forward infrastructure for observability.
The New Observability Mandate
The expectations for observability systems today are much higher than when those systems were first created. Modern organizations require observability solutions that are fast, adaptable, consistent across different environments, and increasingly enhanced by machine learning and automation. This change is not optional; it is the natural result of how software has developed.
Distributed systems produce distributed telemetry. Every service, node, pod, function, and proxy contributes its own signals: traces, logs, metrics, events, and metadata form overlapping but incomplete views of the truth. Observability platforms strive to provide teams with a unified view, but they often inherit data that is inconsistent or poorly structured. The responsibility to interpret the data shifts downstream, and the platform becomes the place where confusion builds up.
Meanwhile, telemetry volume is increasing rapidly. Most organizations collect data much faster than they can analyze it. Costs rise with data ingestion and storage, not with gaining insights. Usually, only a small part of the collected telemetry is used for investigations or analytics, even though teams feel the need to keep collecting it. What was meant to improve visibility now overwhelms the very clarity it aimed to provide.
Finally, observability must advance from basic instrumentation to something smarter. Modern systems are too complex for human operators to interpret manually. Teams need observability that helps answer not just “what happened,” but “why it happened” and “what matters right now.” That transition requires a deeper understanding of telemetry at the data level, not just more dashboards or alerts.
These pressures lead to a clear conclusion. Observability requires a new architectural foundation that considers data as the primary product, not just a byproduct.
Why Observability Architectures are Cracking
When you step back and examine how observability stacks developed, a clear pattern emerges. Most organizations did not intentionally design observability systems; they built them up over time. Different teams adopted tools for tracing, metrics, logging, and infrastructure monitoring. Gradually, these tools were linked together through pipelines, collectors, sidecars, and exporters. However, the architectural principles guiding these integrations often received less attention than the tools themselves.
This piecemeal evolution leads to fragmentation. Each tool has its own schema, enrichment model, and assumptions about what “normal” looks like. Logs tell one story, metrics tell another, and traces tell a third. Combining these views requires deep expertise and significant operational effort. In practice, the more tools an organization adds, the harder it becomes to maintain a clear picture of the system.
Silos are a natural result of this fragmentation, leading to many downstream issues. Visibility becomes inconsistent across teams, investigations slow down, and it becomes harder to identify, track, and understand correlations across different data types. Data engineers must manually translate and piece together telemetry contexts to gain deeper insights, which creates technical debt and causes friction for the modern enterprise observability team.
Cost becomes the next challenge. Telemetry volume increases predictably in cloud-native environments. Scaling generates more signals. More signals lead to increased data ingestion. Higher data ingestion results in higher costs. Without a structured approach to parsing, normalizing, and filtering data early in its lifecycle, organizations end up paying for unnecessary data processing and can't make effective use of the data they collect.
Complexity adds another layer. Traditional ingest pipelines weren't built for constantly changing schemas, high-cardinality workloads, or flexible infrastructure. Collectors struggle during burst periods. Parsers fail when fields change. Dashboards become unreliable. Teams rush to fix telemetry before they can fix the systems the telemetry is meant to monitor.
Even the architecture itself works against teams. Observability stacks were initially built for stable environments. They assume predictable data formats, slow-moving schemas, and a manageable number of sources. Modern environments break each of these assumptions.
And beneath it all lies a deeper issue: telemetry is often gathered before it is fully understood. Downstream tools receive raw, inconsistent, and noisy data, and are expected to interpret it afterward. This leads to a growing insight gap. Organizations collect more information than ever, but insights do not keep up at the same rate.
The Architectural Root Cause
Observability systems were built around tools rather than a unified data model. The architecture expanded through incremental additions instead of being designed from first principles. The growing number of tools, along with the increased complexity and scale of telemetry, created systemic challenges. Engineers now spend more time tracking, maintaining, and repairing data pipelines than developing systems to enhance observability. The unexpected surge in complexity and volume overwhelmed existing systems, which had been improved gradually. Today, Data Engineers inherit legacy systems with fragmented and complex tools and pipelines, requiring more time to manage and maintain, leaving less time to improve observability and more on fixing it.
A modern observability system must be designed to overcome these brittle foundations. To achieve adaptive, cost-efficient observability that supports AI-driven analysis, organizations need to treat telemetry as a structured, governed, high-integrity layer. Not as a byproduct that downstream tools must interpret and repair.
The Shift Upstream: Intelligence in the Pipeline
Observability needs to begin earlier in the data lifecycle. Instead of pushing raw telemetry downstream, teams should reshape, enrich, normalize, and optimize data while it is still in motion. This single shift resolves many of the systemic issues that plague observability systems today.
AI-powered parsing and normalization ensure telemetry is consistent before reaching a tool. Automated mapping reduces the operational effort of maintaining thousands of fields across numerous sources. If schemas change, AI detects the update and adjusts accordingly. What used to cause issues becomes something AI can automatically resolve.
The analogy is straightforward: tracking, counting, analyzing, and understanding data in pipelines while it is streaming is easier than doing so when it is stationary. Volumes and patterns can be identified and monitored more effortlessly within the pipeline itself as the data enters the system, providing the data stack with a better opportunity to comprehend them and direct them to the appropriate destination.
Data engineering automation enhances stability. Instead of manually built transformations that fail silently or decline in quality over time, the pipeline becomes flexible. It can adapt to new event types, formats, and service boundaries. The platform grows with the environment rather than being disrupted by it.
Upstream visibility adds an extra layer of resilience. Observability should reveal not only how the system behaves but also the health of the telemetry that describes it. If collectors fail, sources become noisy, fields drift, or events spike unexpectedly, teams need to know at the source. Troubleshooting starts before downstream tools are impacted.
Intelligent data tiering is only possible when data is understood early. Not every signal warrants the same storage cost or retention period. By assessing data based on relevance rather than just time, organizations can significantly reduce costs while maintaining high-signal visibility.
All of this contributes to a fundamentally different view of observability. It is no longer something that happens in dashboards. It occurs in the pipeline.
By managing telemetry as a governed, intelligent foundation, organizations achieve clearer visibility, enhanced control, and a stronger base for AI-driven operations.
How Databahn Supports this Architectural Future
In the context of these structural issues shaping the future of observability, it is essential to note that AI-powered pipelines can be the right platform for enterprises to build this next-generation foundation – today, and not as part of an aspirational future.
Databahn provides the upstream intelligence described above by offering AI-powered parsing, normalization, and enrichment that prepare telemetry before it reaches downstream systems. The platform automates data engineering workflows, adjusts to schema drift, offers detailed visibility into source telemetry, and supports intelligent data tiering based on value, not volume. The result is an AI-ready telemetry fabric that enhances the entire observability stack, regardless of the tools an organization uses.
Instead of adding yet another system to an already crowded ecosystem, Databahn helps organizations modernize the architecture layer underneath their existing tools. This results in a more cohesive, resilient, and cost-effective observability foundation.
The Path Forward: AI-Ready Telemetry Infrastructure
The future of observability won't be shaped by more dashboards or agents. Instead, it depends on whether organizations can create a stable, adaptable, and intelligent foundation beneath their tools.
That foundation starts with telemetry. It needs structure, consistency, relevance, and context. It demands automation that adapts as systems change. It also requires data that is prepared for AI reasoning.
Observability should move from being tool-focused to data-focused. Only then can teams gain the clarity, predictability, and intelligence needed in modern, distributed environments.
This architectural shift isn't a future goal; it's already happening. Teams that adopt it will have a clear edge in cost, resilience, and speed.
Subscribe to DataBahn blog!
Get expert updates on AI-powered data management, security, and automation—straight to your inbox
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
By clicking "Accept", you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.
Oops! Something went wrong while submitting the form.
Hi 👋 Let’s schedule your demo
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
“It's amazing that a data pipeline tool can do this level of pre-processing to filter out irrelevant data and produce insights."
Ricky Allen
,
Chief Technology Officer
|
CyberOne Security
We have recently started a journey with DataBahn and I can’t speak highly enough about the product or the amazing team at Databahn.
Greg Stewart
,
Senior Director, Cybersecurity
|
CSL Behring
I was lucky enough to get a demo of DataBahn and was blown away at the capabilities and the impact the platform will deliver.
Keith Schlosser
,
Group CIO
|
AXIS Capital
"We reduced 70% of our data going to our SIEM. And here’s the game-changer: no ingress, egress, or API fees."
Abraham Selvaraj
,
Director, Information Security
|
ThinkOn
While DataBahn.ai is a perfect use case for SIEM solutions like Sentinel, I believe its use case is even broader as the "Data Pump" for all enterprise data.
Michael Keithley
,
Member, Board of Directors
|
Fractional CIO/CTO, Former CIO/CTO at CAA & UTA
"Databahn’s approach has truly simplified Sentinel, making it more efficient and cost-effective."









.avif)





.avif)

.avif)







